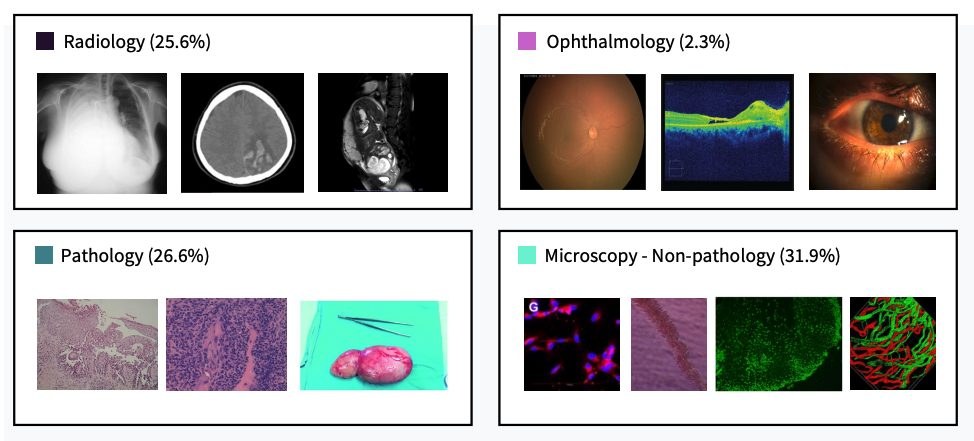
做醫學多模態模型,最難往往不是再堆一個新架構,而是先整理到可用的圖文資料。MedPMC 屬於Dataset 數據集加模型訓練程式碼項目,核心價值是把 PubMed Central (PMC) 文獻中的醫學圖片與文字抽取、清理,再接上訓練與評估流程,處理的是醫學 vision-language 資源長期分散、難重現的問題。
目前最值得留意的是 MedPMC Dataset 首個版本,提供約 1,100 萬組 medical image-text pairs;同時亦有基於 MedPMC-11M 訓練的 MedPMC-CLIP。這種做法與不少只放模型權重、或只交出資料連結的項目不同,它把 dataset curation、preprocessing、model training、evaluation 放在同一個代碼庫,較適合研究團隊沿住同一條流程再做微調或重跑實驗。
部署與測試的理解方式很直接:資料集與模型都已放到 Hugging Face,現階段較像給研究者先下載資料、檢查抽樣品質、再接入自家訓練管線。README 未提供很完整的操作文件,dataset viewer 亦未必可直接預覽,所以短期內它比較偏向有 Python 與資料處理能力的團隊,而不是即開即用的線上服務。
- 約 1,100 萬組來自 PMC 的醫學圖文配對,是項目現時最重要資產
- 連同 MedPMC-CLIP 一併釋出,方便由資料走到模型驗證
- 重點不在花巧介面,而在可重現的資料整理與訓練流程
- 文件仍在補完中,benchmarks 與更多 training recipes 尚待發布
以現有資訊看,MedPMC 的強項是規模與研究流程整合,限制則是文件與基準結果仍未齊備,暫時較難單靠公開頁面判斷模型表現上限。對醫學 AI、視覺模型、RAG 前處理,或需要建立醫學圖文檢索基座的團隊來說,這個開源項目已有不錯參考價值;相關模型現時可確認的是 MedPMC-CLIP。