Google 推出了 Gemini CLI,一個免費的開源項目。它允許開發者透過自然語言指令在 Terminal 使用 Google 的 Gemini 2.5 Pro 模型。它可以編寫程式碼,亦能夠處理內容的生成、或者解決問題、甚至深入研究和任務管理等的多種任務。這個工具的設計目標是提升開發者在終端機中的工作效率,令 AI 成為日常工作流程的一部分。

Google 推出了 Gemini CLI,一個免費的開源項目。它允許開發者透過自然語言指令在 Terminal 使用 Google 的 Gemini 2.5 Pro 模型。它可以編寫程式碼,亦能夠處理內容的生成、或者解決問題、甚至深入研究和任務管理等的多種任務。這個工具的設計目標是提升開發者在終端機中的工作效率,令 AI 成為日常工作流程的一部分。
Python UV 是一個以 Rust,編寫的高效能 Python 套件管理器和安裝程式。它能夠簡化 Python 的開發,同時負責管理標準函式庫(Standard Library),或者安裝虛擬環境等等。影片詳細講解了點樣利用 UV 進行完整的開發流程,並且強調 UV 在簡化和統一開發環境方面的優勢。

wp-ai-chat 是個開源的 WordPress 插件,旨在為 WordPress 網站整合 AI 助手功能。這個插件可以連接多種不同的 AI 模型,包括 DeepSeek、豆包、通義千問、OpenAI、Kimi 和千帆等,提供聊天、文章翻譯和 AI 生成 PPT 等功能。
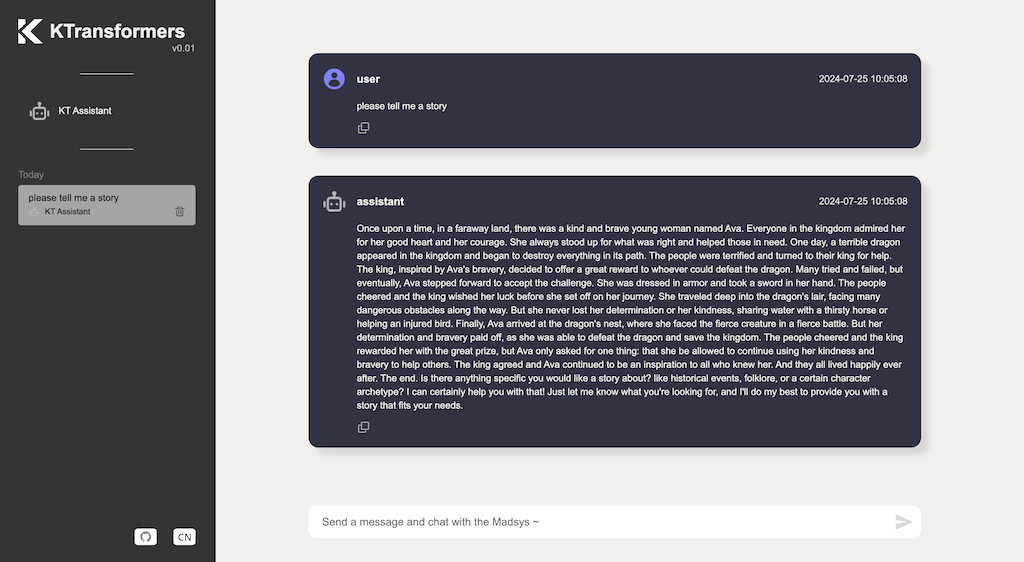
KTransformers 透過先進的核心優化技術來增強 Transformers 的體驗。KTransformers 特別為硬件資源有限的本地部署,並支援異構運算,例如量化模型的 GPU/CPU 卸載,令到不同的架構處理器可以協同工作。KTransformers 亦提供了一個 YAML 範本來呼叫特殊的優化指令。结果可以令 RTX 4090 本地運行 DeepSeek-R1、V3 的 671 B 满血版,以 24 Gig VRam 最高推理速度仍達到 14 tokens/s。當然,你亦需要保証足夠 D Ram。
這影片教你如何使用 DeepSeek AI 和 Crawl4AI 驅動網頁爬蟲,甚至無需編寫任何程式,就能輕鬆地從任何網站收集結構化數據。影片同時亦展示了一個實際案例,講解點樣為公司尋找潛在客戶,包括地址、企業名稱和聯絡方式等資訊,然後將數據匯入試算表進行整理和分析。

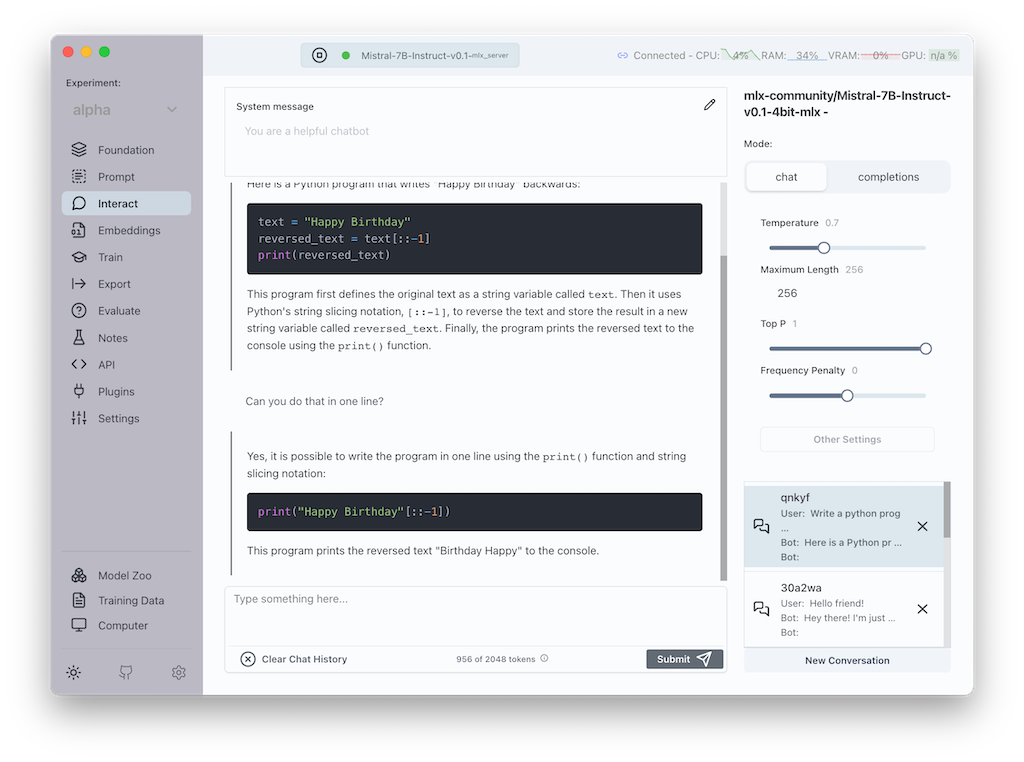
Transformer Lab 是個免費的開源 LLM 工作平台,方便進行微調、評估、匯出和測試,並支援唔同的推理引擎和平台。Transformer Lab 適用於擁有 GPU 或 TPU 的電腦,亦支援 MLX 的 M 系列的蘋果電腦。主要功能包括下載開源模型、智能聊天、計算嵌入、創建和下載訓練數據集、微調和訓練 LLM、以及使用 R A G 與文件互動。

![]()
OpenHealth 專案是一個開源的 AI 健康助理,作者描述自己五年來花費超過十萬美元、看過三十多位醫生,卻無法確診自體免疫疾病的痛苦過程。 受到這個經歷的啟發,他開發了一個開源 AI 工具,可以幫助人們分析自己的醫療記錄,從不同的醫院提取並整理數據,並藉由 AI 模型進行分析,找出潛在的疾病。 這個工具的目的是解決醫療資訊分散的問題,讓患者能夠更全面地了解自己的健康狀況,並提供給醫生參考,但作者也強調,此工具僅為輔助診斷,不能取代專業醫療人員的判斷。
open-deep-research 是個開源的深度研究工具,模仿 OpenAI 的 Deep Research 實驗,但使用 Firecrawl 擷取和搜尋網頁資料,並結合推理模型,而非微調 o3 模型。 專案以Next.js建構,具有多種功能,包含即時資料饋送、結構化資料擷取、先進路由、支援多種大型語言模型(LLM)如 OpenAI、Anthropic 和 Cohere),當然亦 Support 免費的 Ollama 以及資料持久化機制。 提供本地部署和執行說明。 整體而言,它展示了一個強大的、可擴展的深度研究工具,並強調其開源和易於使用的特性。
Cherry Studio 是一款支持多個大語言模型(LLM)服務商的桌面客戶端,兼容 Windows、Mac 和 Linux 系統。支持主流 LLM 云服务:OpenAI、Gemini、Anthropic、硅基流动等。支持 Ollama 本地模型部署。内置 300+ 预配置 AI 助手。

![]()
MangaNinja 的主要設計目標是基於協助線稿圖像上色。它採用了幾個關鍵技術:區塊隨機置換模組(patch shuffling module),點驅動控制方案(point-driven control scheme)。實驗結果顯示,MangaNinja 在色彩準確度和生成圖像質量方面明顯優於其他現有的非生成式著色方法(如 BasicPBC)、一致性生成方法(如 IP-Adapter)以及 AnyDoor。總結來說,MangaNinja 透過區塊隨機置換模組和點驅動控制方案實現精確的線稿著色。它不僅可以處理單一參考圖像,還可以利用多個參考圖像進行著色,並且可以處理參考圖像與線稿之間存在差異的情況。此外,MangaNinja 的互動式控制功能,允許使用者更精確地控制著色結果。
