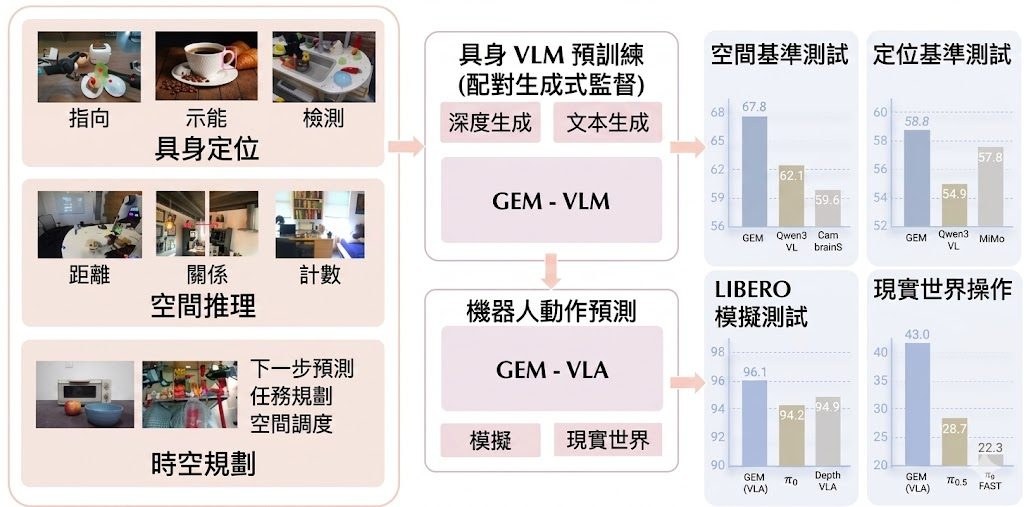
GEM(Generative-supervised Embodied vision-language Model)是一個面向具身智能的 Vision-Language Models(VLMs)項目,重點不是只靠文字與圖片對答,而是讓模型同時學會場景的空間結構。它加入了深度圖生成這個輔助目標,希望補足一般文字驅動預訓練較少接觸的物理與幾何訊息,令模型不只「看得明」,也更接近「知道怎樣在空間中行動」。
這個設計想解決的問題很清楚:很多模型在語意理解、問答和描述表現不錯,但一牽涉到距離、遮擋、方向、可操作位置,或者下一步應怎樣做,能力就未必跟得上。GEM的做法,是在預訓練階段直接把 depth map generation 放進去,令模型在學文字生成時,也學場景深度與結構。論文亦提到其方法結合 hybrid autoregressive-diffusion architecture,並以 progressive training strategy 先穩定生成模組,再聯合訓練。
GEM 比較適合研究與實驗用途。倉庫已提供 GEM-2B checkpoint、GEM-250K 資料樣本,以及 VLM training / inference 代碼;要動手測試,主要是先準備 Python 3.10+ 環境與 torch、transformers、deepspeed、flash-attn 等依賴,再把資料路徑、depth image 路徑、MODEL_PATH 和 OUTPUT_DIR 設定好。由於資料位置需要手動修改到程式檔案內,整個流程不像一般即開即用工具,比較像給熟悉模型訓練流程的人做重現、微調或延伸開發。
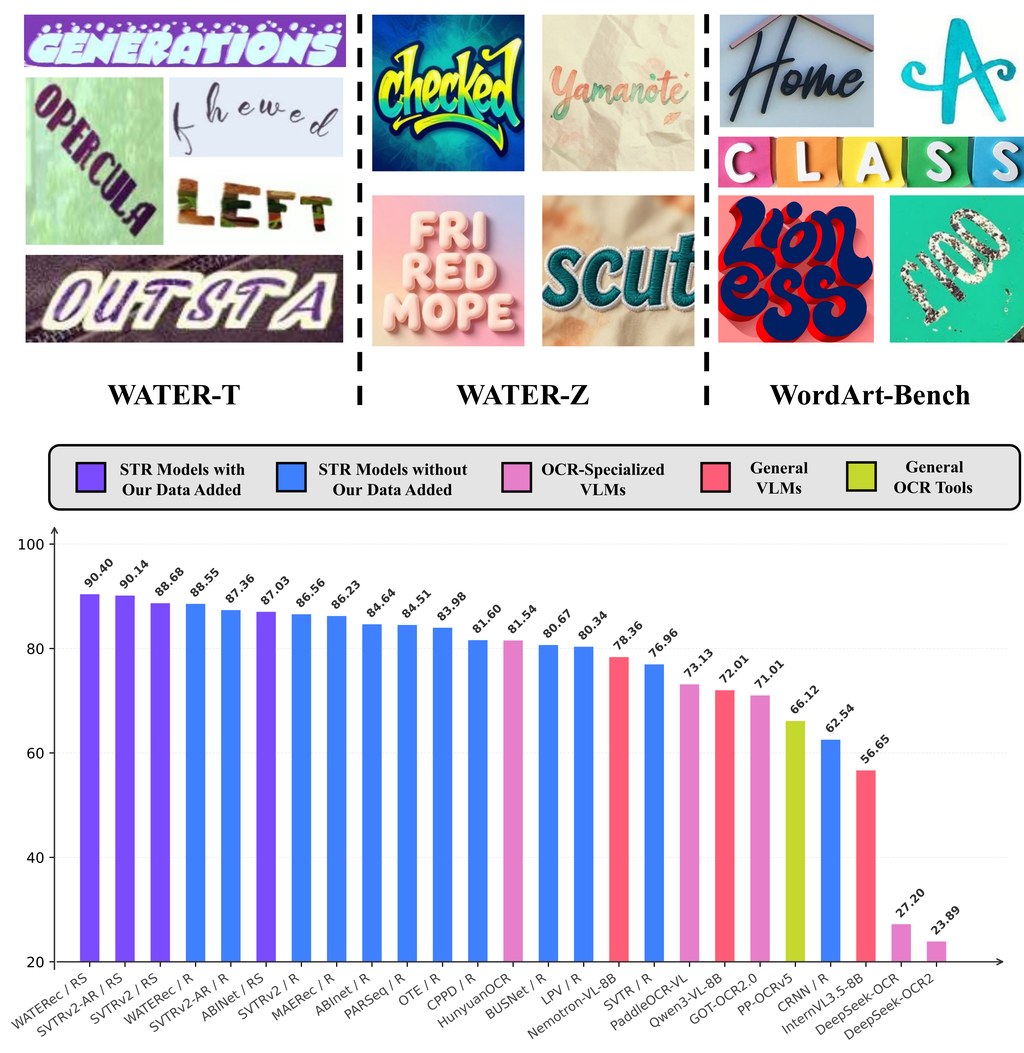
項目的亮點不止於模型結構,還包括資料方向。README 提到釋出的是 GEM-250K 樣本,而論文內容則描述了更大規模的 GEM-4M,涵蓋 grounding、reasoning、planning 以及 depth supervision。這表示團隊的重點不只是堆大模型參數,而是把具身任務常見的空間理解、時序規劃和物理推理,放進同一套訓練資料與目標內,這對 Embodied VLMs 走向 Vision-Language-Action Models(VLA)相當關鍵。
核心方法是在 VLM 預訓練中加入 depth map generation,強化 physical grounding 與 spatial reasoning
已公開的相關資源包括 GEM-2B、GEM-250K,以及訓練與推論代碼
延伸版本 GEM-VLA 面向 Vision-Language-Action Models(VLA)與機械人操作
依賴包含 torch>=2.6.0、transformers>=4.57.0、deepspeed、flash-attn、accelerate、peft、triton、torchcodec
現階段較適合研究人員、ML 工程師,或想重現論文結果的團隊
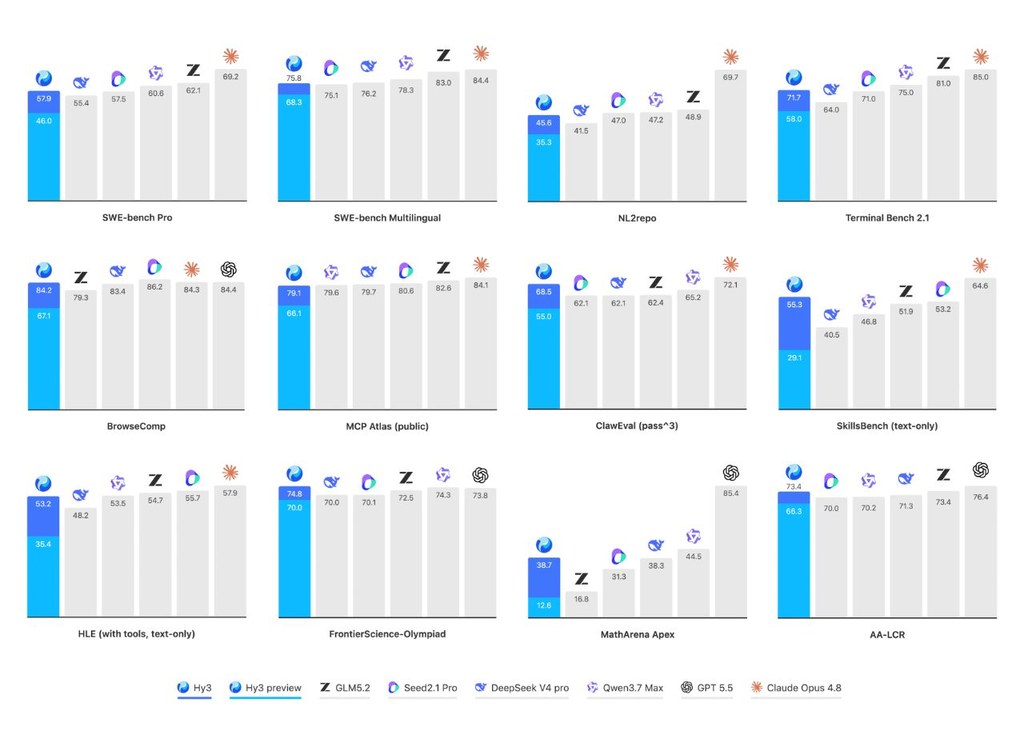
性能方面,GEM 在多個 embodied benchmarks 上有強勁表現,而論文內容則進一步指出 GEM 與 GEM-VLA 在 diverse embodied benchmarks、LIBERO 模擬環境,以及 real-world robot tasks 取得 state-of-the-art results。從公開資訊可見,它比較的是空間推理、grounding 與任務執行能力,而不只是通用聊天或圖文問答分數。不過,倉庫頁面未完整列出所有可重現的評測表格與設定細節,使用時仍應以論文和後續釋出的完整資料為準。
整體來看,GEM最適合關注機械人、多模態學習、Embodied Intelligence 的讀者留意。若你正在找的是一個現成聊天助手,這個項目未必對口;但若你想了解下一代模型怎樣由「看圖答題」走向「理解空間並支援動作決策」,GEM提供了一條很具代表性的路線。相關模型與基礎包括 GEM、GEM-2B、待釋出的 GEM-8B、延伸版本 GEM-VLA,以及其代碼所建基的 Qwen3-VL、Sana、RDT2。
GitHub: https://github.com/zhaorw02/GEM
Paper: https://arxiv.org/pdf/2605.28548