SGT 是一個研究味較重的項目,核心想法是用「圖像分割」作為生成式微調的代理任務,讓同一個多模態模型不只看得明,亦畫得更準。它針對的痛點很清楚:不少統一多模態模型會把理解與生成分開優化,結果兩邊能力未必真正協同。
這個項目的亮點,在於它沒有再把重心放在像素紋理,而是改用較高層次的語意結構作監督。簡單講,模型不是只學顏色和邊緣,而是學物件區域與空間關係,這對圖片理解,以及按位置生成內容,都更有幫助。
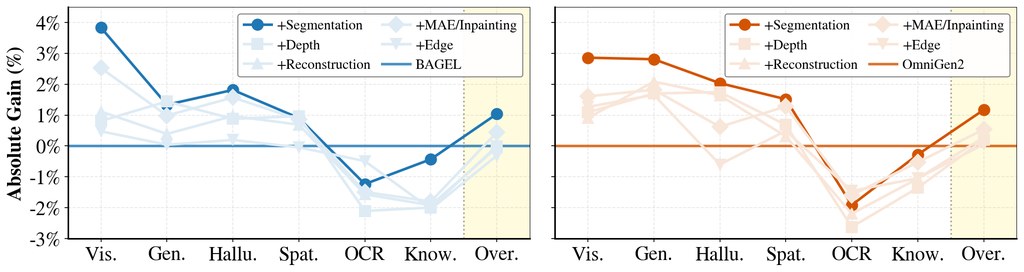
從 README 提供的結果來看,SGT 曾在 BAGEL(7B+7B)和 OmniGen2(3B+4B)上驗證,顯示它不是綁死單一架構的做法。研究亦比較了 edge、depth、segmentation 三類代理任務,結論偏向一致:segmentation 在理解能力提升上表現最好,而生成的空間準確度亦有改善;至於數學或圖表推理,就未見明顯幫助。
想了解這個項目,可先看論文與項目頁,再留意其公開資料集 SAM-SGT,重點不是立即部署,而是理解這套訓練思路如何套入現有多模態模型。對研究人員、模型訓練工程師,或關心視覺理解與生成整合的人,這個方向特別值得留意。
- 以圖像分割作生成式微調代理,連接理解與生成
- 已在 BAGEL 與 OmniGen2 驗證,具一定架構通用性
- 比起 edge、depth,segmentation 更能提升視覺理解表現
- 生成結果的空間對位更穩,尤其適合位置敏感提示
- 分割資料越多,表現有持續上升趨勢
整體來說,SGT 吸引之處不在花巧功能,而在提出一條頗務實的訓練路線:用高層語意監督,補回多模態模型常見的理解與生成落差。若你關注 UMM 後訓練方法,這個項目很值得放入觀察名單。
GitHub: https://github.com/song2yu/SGT