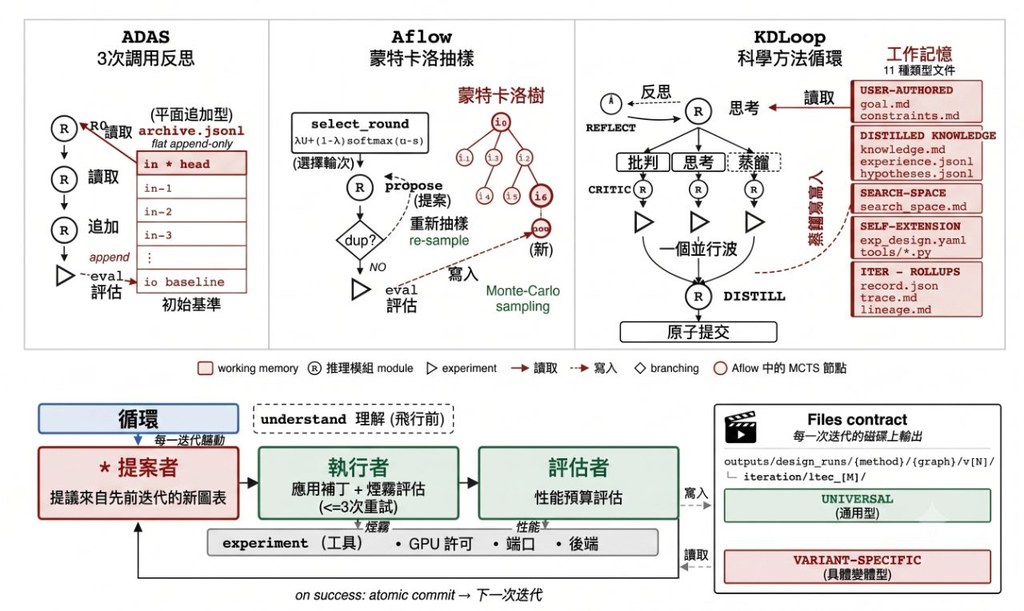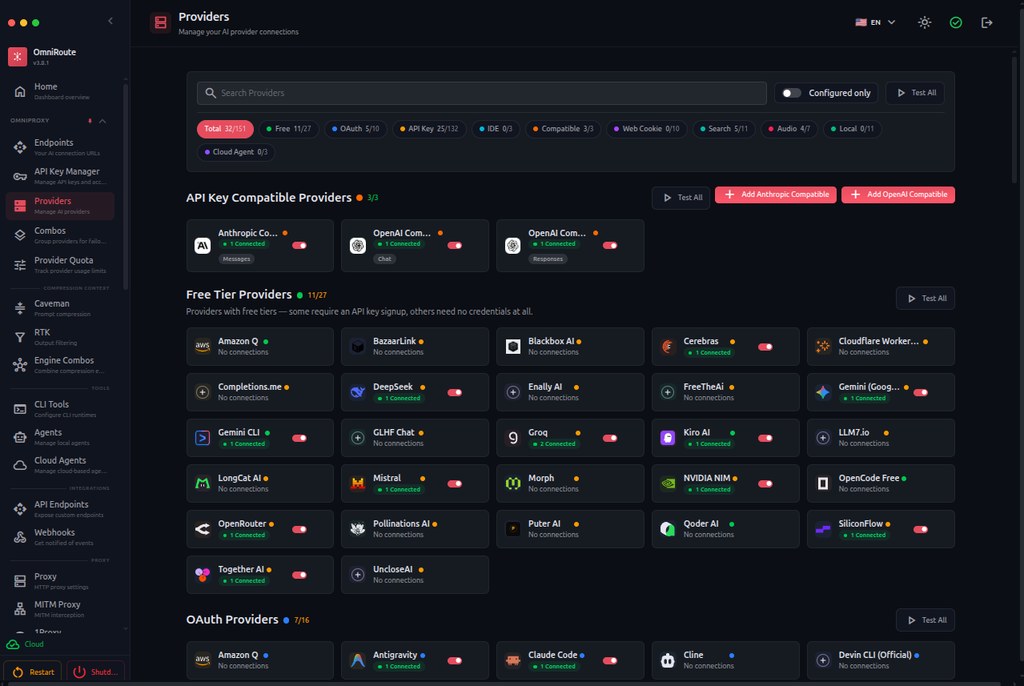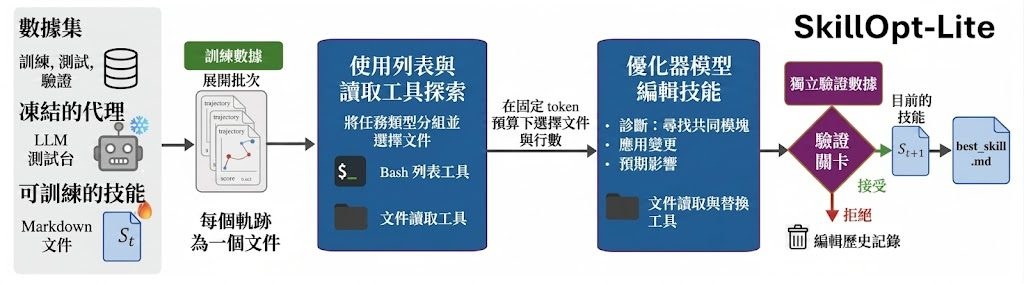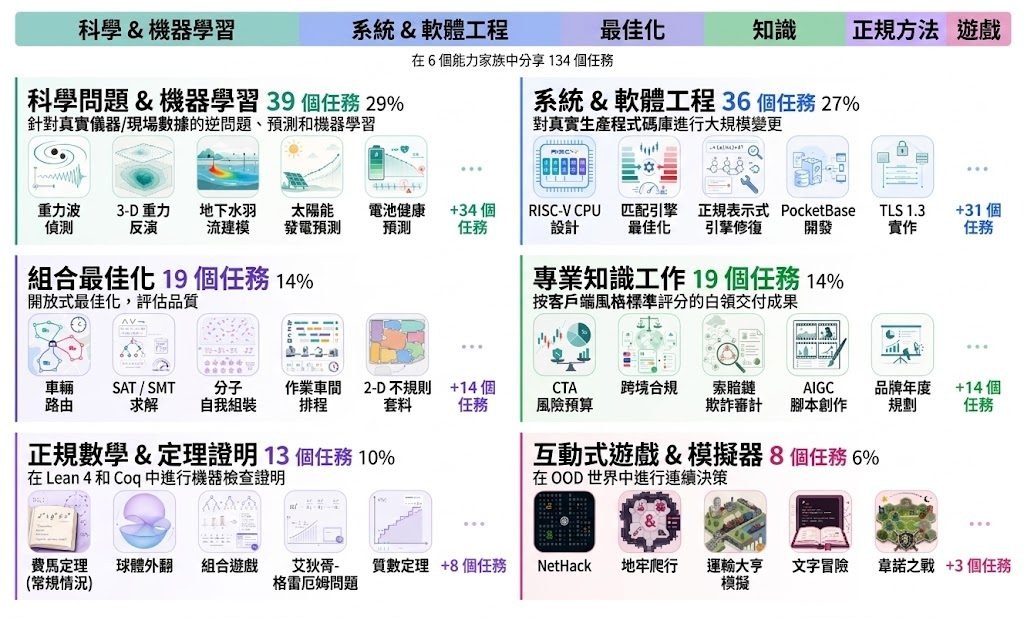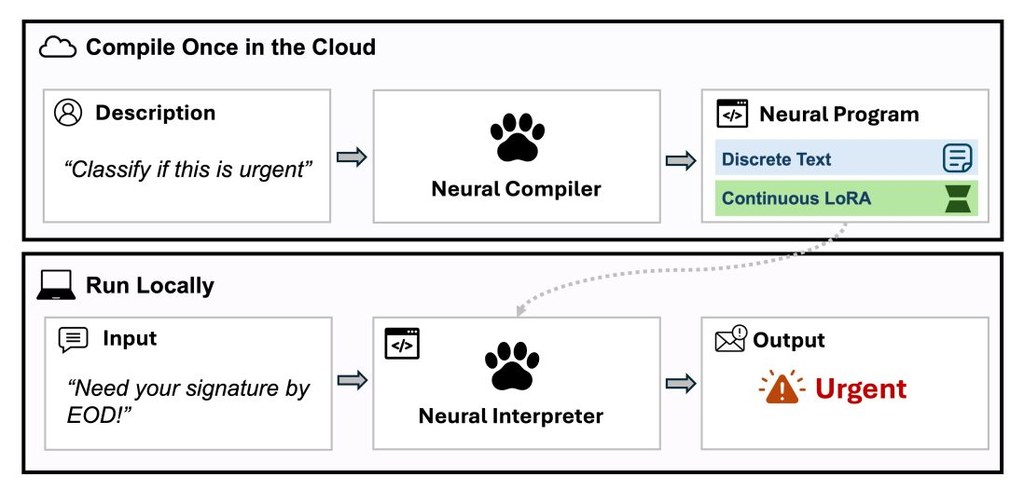
想喺自己電腦上跑到規模較大的多模態模型,最大卡位通常唔係功能,而係記憶體同速度。Qwen3.6 屬於阿里巴巴的新一代多模態 hybrid-thinking 模型系列,重點在於用相對可控的硬件需求,處理 agentic coding、vision 同 chat 等工作。
現有資料提到兩個主力型號:Qwen3.6-27B 同 35B-A3B。前者可在約 18GB 記憶體配置下運行,後者約需 22GB 至 23GB 左右,並支援 256K context 及 201 種語言。對想喺本地做長內容理解、跨語言對話,或者配合工具調用工作流的人來說,這個取向幾實用。
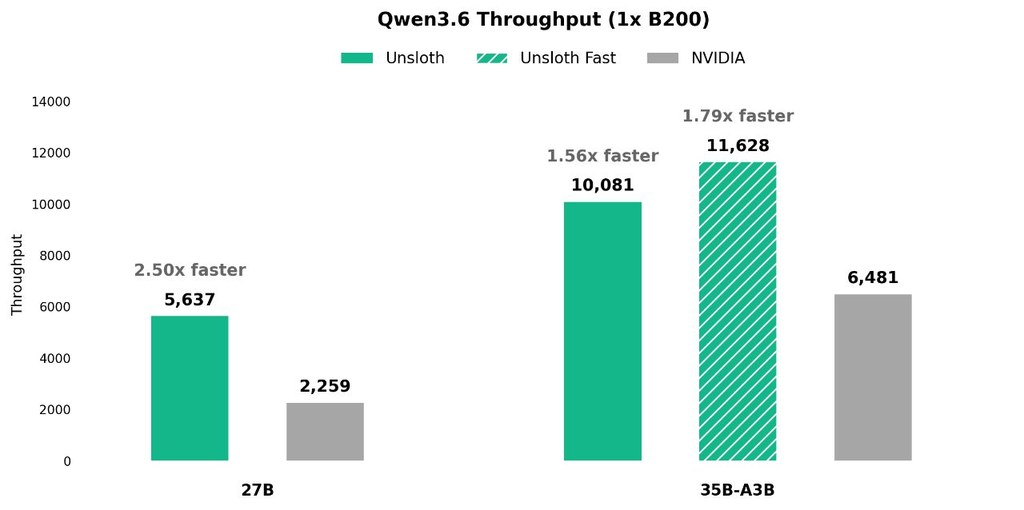
相比只講「可量化、可本地跑」的常見做法,Unsloth 這邊更著重點樣揀到速度與準確度較平衡的版本。Qwen3.6 GGUFs 採用 Unsloth Dynamic 2.0,會按真實使用資料做 calibration,並把重要 layers upcast;另外新推出的 NVFP4 quants 主打在 GPU 上帶來約 2.5 倍更快速度,MTP 則標示可把 inference 再加快 1.4 至 2.2 倍,同時不犧牲準確度。
- 適合本地部署多模態模型,兼顧編碼、視覺與對話
- 27B、35B-A3B 記憶體需求相對克制,較易在個人設備起步
- GGUF 格式配合 Unsloth Dynamic 2.0,重點是量化後仍保持可用表現
- NVFP4 與 MTP 主要改善推理速度,幫助減少等待時間
使用上仍有幾點要留意:總可用記憶體最好高於下載的量化模型大小,否則雖然可經 llama.cpp 用 SSD/HDD offloading 繼續運行,但推理會慢得多;文件亦明確提醒不要使用 CUDA 13.2,以免輸出異常。整體來看,這不是單純把 Qwen3.6 搬到本地,而是把「跑得動、跑得快、精度仍可接受」這幾個取捨整理得更清楚。
所引用的模型列表:Qwen3.6-27B、Qwen3.6-35B-A3B。