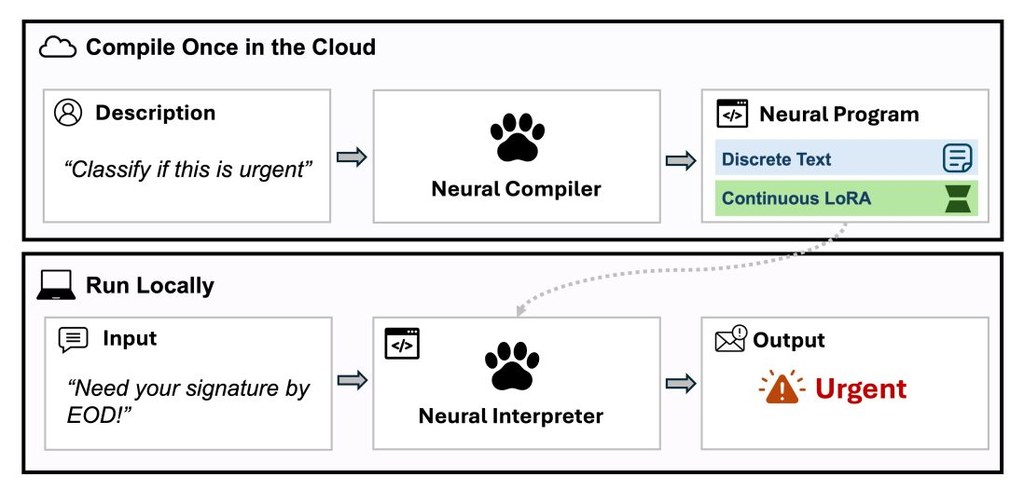
PAW(programasweights-python)是一個 Python 工具兼研究原型,屬於把「自然語言」規格編譯成小型神經函數的項目。它要解決的是一類很難用正則表達式或硬編碼規則寫穩定的工作,例如修復壞掉的 JSON、模糊搜尋、分類、抽取欄位,以及把文字意圖對應到正確操作。
現有做法通常有兩條路:一條是手寫規則,遇到錯字、格式飄移同邊界情況就容易失準;另一條是把每次輸入都送去 LLM API,換來較高彈性,但會帶來網絡依賴、成本同重現性問題。Program-as-Weights(PAW)提出的做法,是先用一個 compiler 把英文描述編譯成可重用的神經程式,之後每次呼叫都在本機執行,定位由「每次都問模型」改成「先造好工具再反覆用」。
安裝路線相當直接:Python 端可透過套件取得預編譯函數,亦可自行 compile;瀏覽器端則有 @programasweights/web,但只限用 paw-4b-gpt2 這條較細的 runtime。部署取捨也寫得清楚,paw-4b-qwen3-0.6b 準確度較高,程式體積約 22 MB,本地推理約 0.05 至 0.5 秒;paw-4b-gpt2 準確度較低,但程式只有約 5 MB,支援 WebAssembly,較適合前端或輕量分發。
項目的技術定位:作者把這類問題稱為 fuzzy-function programming,並釋出 FuzzyBench 這個 10M examples 數據集,用 4B compiler 為 frozen interpreter 產生 parameter-efficient adapters。文中指出,0.6B Qwen3 interpreter 執行 PAW 程式時,效果可接近直接 prompting Qwen3-32B,同時把推理記憶體壓到約五十分之一,並在 MacBook M3 達到 30 tokens/s;這些數字有助理解它不是單純包裝模型,而是在成本、可重用性與離線能力之間重新分配。
- 核心價值:把一次性的自然語言需求,轉成可重複呼叫的本地函數
- 適合情境:日誌分流、格式修復、文字分類、資料抽取、意圖路由
- 主要取捨:比直接調用大型 API 更可控、可離線,但編譯器與 runtime 選型會影響準確度與體積
- 相關模型:
paw-4b-qwen3-0.6b、paw-4b-gpt2,論文亦以 Qwen3-32B 作對照 - 受益團隊:重視本地執行、穩定輸出、低成本重複推理的開發團隊會較易受惠
這個項目最適合放在「規則太脆弱、API 又太重」的中間地帶。它未必取代通用 LLM,但對一批固定任務而言,先編譯、後離線執行的方式更像真正可落地的工程工具。