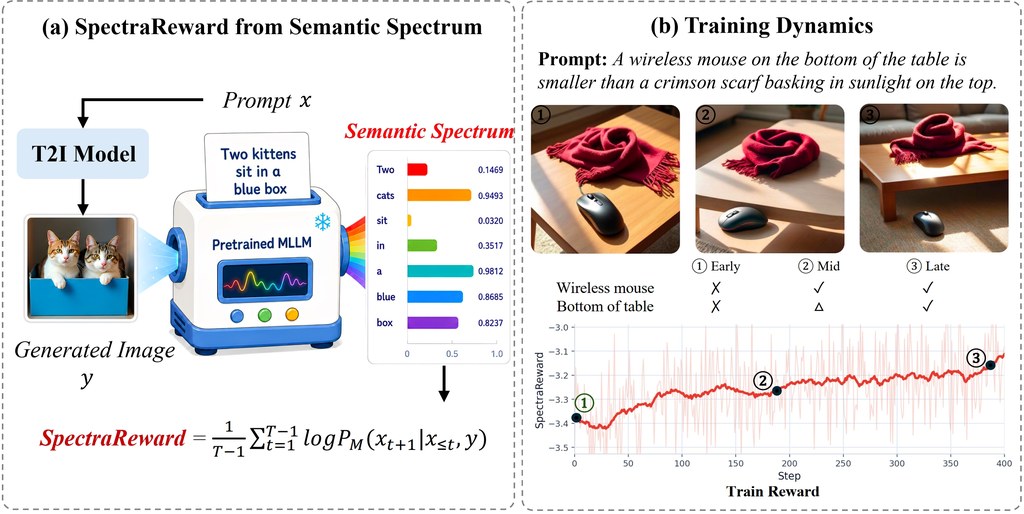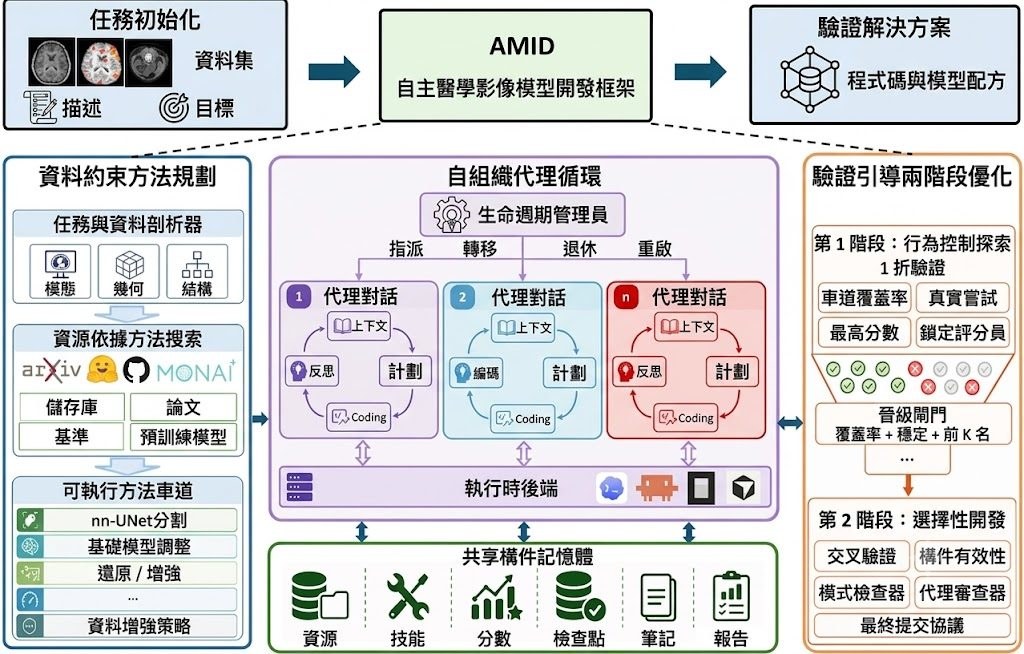
醫學影像建模最麻煩的位,往往唔係只係揀網絡,而係每個任務都有唔同資料形態、指標、切分規則同提交要求。AMID把呢個痛點拉到枱面:它屬於一個 autonomous multi-agent framework,目標唔係產生一段建議文字,而係交出可訓練、可推理、可驗證、可提交的完整模型產物。
現有通用 MLE agent 往往沿用比較粗略的搜尋與試錯範式,先提方案、再寫碼、再靠結果反覆修補;作者認為放到醫學影像場景,呢種做法容易忽略資料條件、驗證協議同提交格式。AMID改用 Data-Conditioned Method Planning,先按任務資料與可運行資源整理出可執行的 method lanes,再用 Verification-Guided Two-Stage Optimization 由早期廣泛探索,轉去後期集中追蹤有潛力路線,同時持續檢查 metric computation、validation protocol 同 prediction artifacts。
呢種取向的差異,在於它把「做得出分數」同「流程可核對」放埋一齊處理。對醫療 AI 團隊、挑戰賽參賽者,或者要同時管理 2D 影像、3D volumes、segmentation masks、class labels 等異質資料的人,AMID的吸引力在於減少人手串接流程的時間;代價是它目前仍以技術報告與任務解法報告為主,README亦寫明 source code 尚未釋出,暫時未到可以直接部署測試的階段。
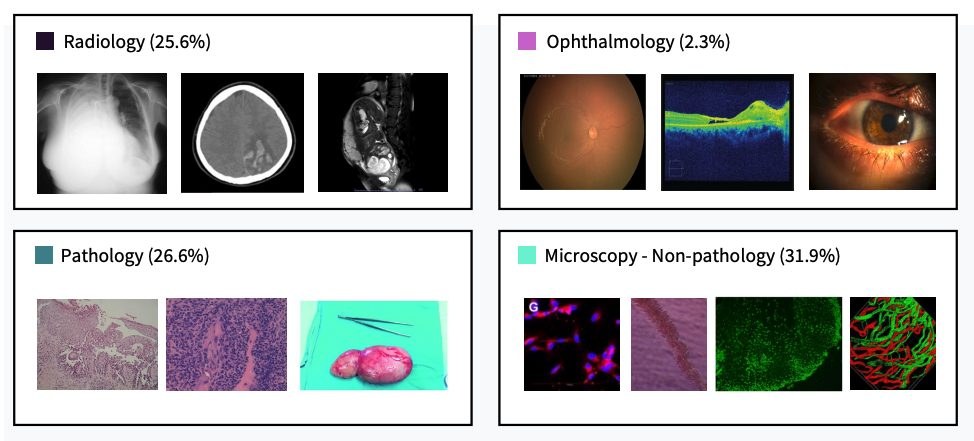
效能方面,AMID用 ReX-MLE 的 20 個 medical imaging challenge tasks 做基準,比較對象包括一般用途 MLE systems,同時拿 human-designed challenge solutions 作參照。作者指出它整體表現優於被評測的通用系統,部分任務接近或追平人手設計方案;現階段較適合把它理解成一套清晰的方法論與工作流藍圖,而唔係即裝即跑的開源工具。
- 核心定位係 autonomous multi-agent framework,處理醫學影像模型開發與驗證交付
- 主要方法包括 Data-Conditioned Method Planning 同 Verification-Guided Two-Stage Optimization
- 輸出唔止模型建議,仲包括 training code、inference code、weights、prediction files 同 audit trail
- 基準測試來自 ReX-MLE 的 20 個任務,整體表現優於通用 MLE systems
- 目前已公開 technical report 同 20 份 solution reports,source code 尚未發布
相關模型與系統脈絡方面,AMID直接對比的是 general-purpose MLE systems,同時以 human-designed challenge solutions 作為高水位參考。它未有把重點放在單一 backbone 或某個固定醫學影像模型,而是把多代理規劃、優化與驗證流程包成可重複的方法,呢點比單次調參工具更值得留意。