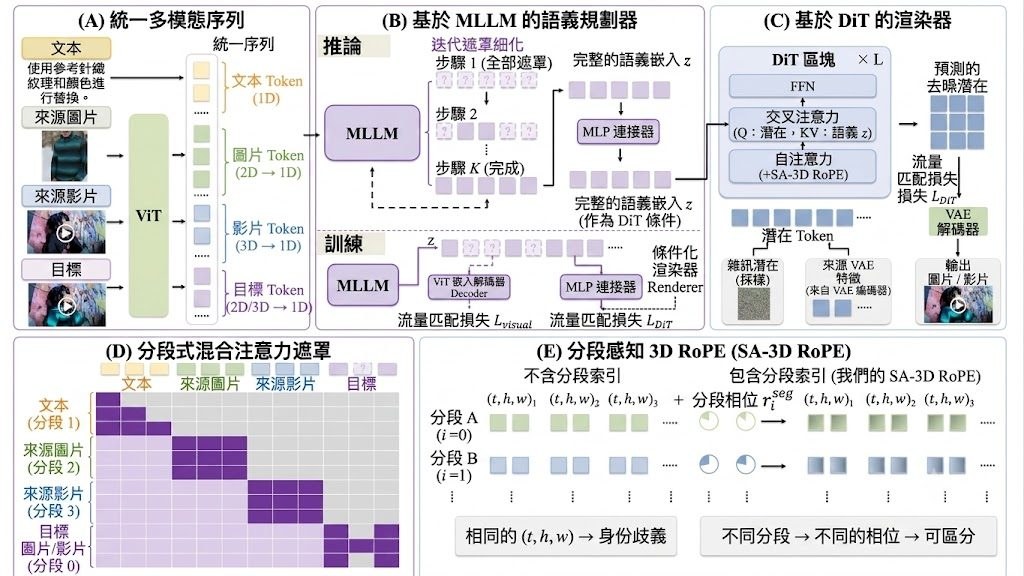
現有 Unified Multimodal Models(UMMs)多數會把影像理解和影像生成分開處理,常見做法是用兩套 visual tokenizers。作者認為這種 fixed paradigm 會把表示空間拆開,模型生成完圖片後,還要再重新編碼才能理解自己剛產生的內容,shared context 也就難以真正成立;UniAR 因此提出一個 unified autoregressive framework,用單一 discrete visual tokenizer 連接理解、生成與編輯。
項目屬於多模態模型,目標是用同一個 Transformer 解決 image understanding、image generation 和 image editing 之間來回切換的成本。它的核心判斷很直接:若模型看圖與作圖共用同一套視覺 token,流程就不需要額外 re-encoding,系統結構會更一致。
技術上,UniAR 有幾個辨識度很高的設計。Multi-level BSQ tokenizer 把高層語意與低層細節一併保留,並透過 Binary Spherical Quantization 擴大有效 vocabulary;parallel bitwise prediction 則把視覺碼以分組方式一齊預測,令 autoregressive 長序列壓短,論文提到 1024×1024 影像只需 256 個 AR tokens,對應 32x visual compression ratio。
- 單一 discrete visual tokenizer 取代雙 tokenizer 架構
- 支援 image understanding、image generation、image editing 同模運作
- Multi-level BSQ tokenizer 同時顧及語意與細節
- parallel bitwise prediction 壓縮視覺序列,加快 autoregressive 生成
- DiT-based visual decoder 以 discrete visual tokens 重建高保真影像
- 需求:Python 3.12、CUDA 12.1+、推理的 GPU 記憶體 >= 24 GB
如果你想試這個項目,較合理的切入點不是直接拿來當日常工具,而是先看它公開的模型權重與項目頁,分開測理解、生成、編輯三類輸出是否一致。它較適合研究多模態統一架構的人、關注 Qwen 生態的開發者,以及想比較 autoregressive 與 diffusion 混合路線的讀者。
性能方面,原文聲稱 UniAR 經 large-scale pre-training、supervised fine-tuning 和 reinforcement learning 後,在 image generation 與 image editing 達到 state-of-the-art,同時在多模態理解 benchmark 保持競爭力。不過目前公開資訊較像研究成果展示,visual decoder training code 仍未完整放出,因此更適合拿來理解方法論,而不是立即評估成成熟生產工具。
相關模型與組件包括 SD3-medium visual decoder、Qwen Team 背景下的多模態模型路線,以及論文聚焦的 Unified Multimodal Models(UMMs)。若你在意的不是單次生成效果,而是模型能否「理解自己生成的內容」,UniAR 的 shared context 設計確實提出了一個有意思而且相當具體的答案。