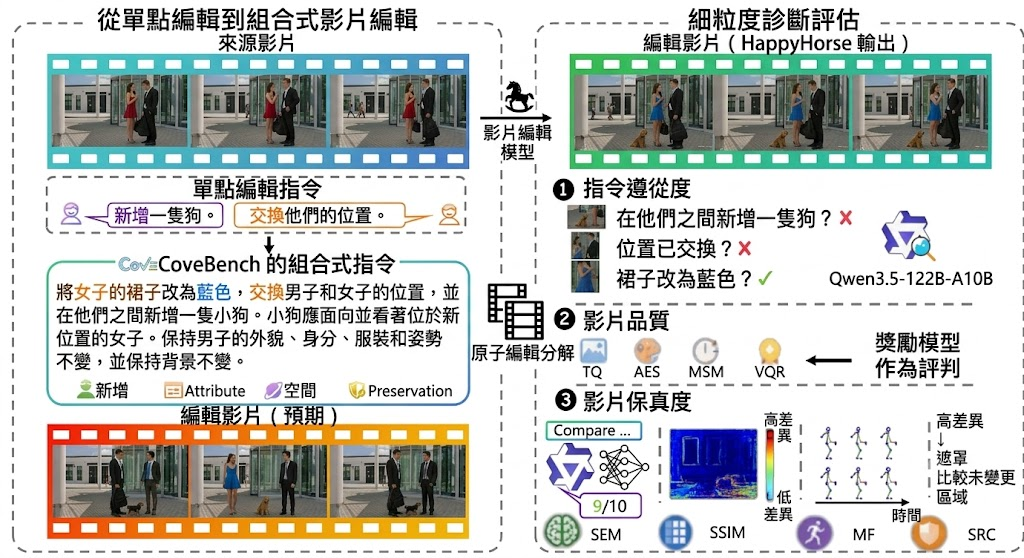
近年不少影片編輯模型已能根據文字改片,但一遇到多個要求同時出現,例如一邊改主體、一邊保留背景與動作連貫,表現就容易失準。CoVEBench 是一個診斷型 benchmark,專門檢查 compositional instruction-guided video editing 在複雜條件下是否真的做得到。
這項目的判斷方法比一般「整體看起來差不多」更嚴格。它把表現分成指令完成度、畫質與來源保真度三條線來看,並用細緻 checklist 檢查多個編輯點有沒有同時成立;就算模型個別要求做到幾項,只要無法通過 union criterion,分數仍然不高,這種設計能更早看出模型短板。
如果想了解它的內容,較合適的做法是先看示範頁與資料集規模,再對照評估指標。CoVEBench 收錄 416 段來源影片、626 條多重指令、9,990 個細項檢查點,預設會抽取 10 張等距 frame 做 frame-level metrics;AES、VQR、MSM 則只針對 edited videos 計算,方便把「改得夠不夠」與「有沒有改壞其他地方」分開分析。
- 核心用途是評測 video editing models,不是直接拿來剪片
- 主要指標包括 Union Accuracy(UAS)、Instruction Following Score(IFS)、Video Realism Score(VRS)、Semantic Consistency(SEM)
- 設計重點在細粒度 checklist,而非只看單一總分
- 結果顯示強模型未必兼顧保留原片內容,編輯力度與保真度存在拉扯
- 項目亦比較了 joint editing 與 stepwise decomposition 的差異,前者表現更好
從公開資訊看,CoVEBench 的價值在於它把失敗原因拆得夠清楚,適合研究團隊、評測人員,以及想比較閉源與開源方案的人參考。相關模型包括 Wan2.7 與 HappyHorse1.0;即使領先系統在複合編輯上較強,UAS 仍未算高,反映這個領域離穩定可靠還有一段距離。