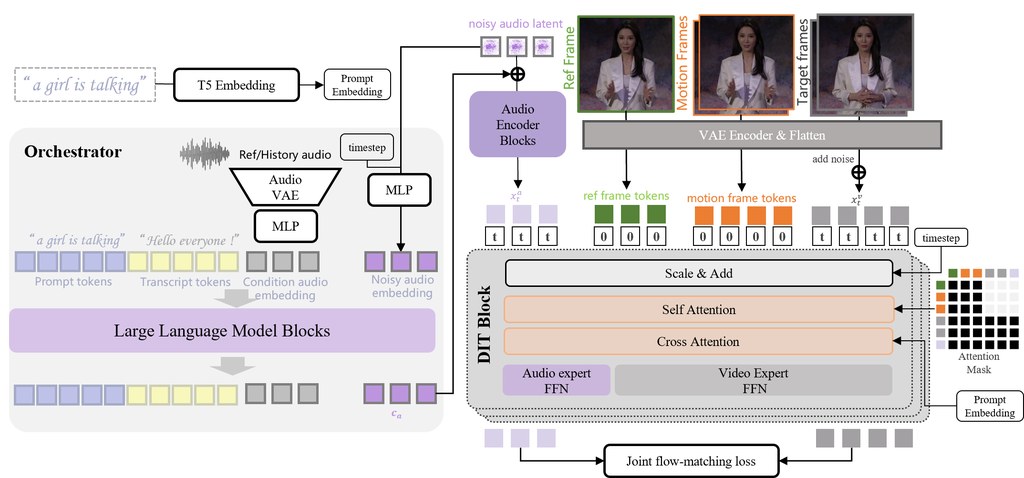
StreamChar 是一個研究展示項目,聚焦 Long-Horizon Streaming Character Audio-Video Generation,也就是長時間、串流式的角色音訊與影片生成。從頁面可見,它的核心組合包括 Decoupled LLM orchestration、joint audio–video DiT denoising backbone、Sink-Chunk Memory,以及 Online Rollout Distillation。
這個項目要處理的重點,是角色聲畫內容在較長輸出過程中的連續性與穩定度。一般生成流程一旦拉長,容易出現內容斷裂、角色狀態不一致,或音訊與畫面節奏不同步;StreamChar 看來就是針對這類長序列生成問題而設計。
使用這個項目時,現階段較像觀看研究成果與示範,而不是直接提供完整產品化操作流程。頁面提供 Paper (arXiv) 與示範影片,適合先從 demo 觀察輸出效果,再配合論文理解整體方法與系統拆分方式。
它的技術方向幾個重點相當清楚:把 LLM 的 orchestration 與底層聲畫生成解耦、以 Streaming DiT Backbone 負責連續生成,並加入 Sink-Chunk Memory 支援長時間上下文。Online Rollout Distillation 則顯示團隊有針對串流生成過程做效率或穩定性上的訓練安排,但頁面摘要未提供更完整數字。
- 聚焦 Long-Horizon Streaming Character Audio-Video Generation
- 結合 Decoupled LLM orchestration 與 joint audio–video DiT denoising
- 以 Sink-Chunk Memory 處理長序列上下文
- 提供研究示範影片,輸出為 native resolution
- 適合關注角色生成、串流生成與多模態研究的人
如果你是做生成式 AI、虛擬角色、數碼人或影片合成相關項目,這個項目有參考價值。至於性能和評估,頁面目前只見方法名稱、論文入口與 demo,未見明確基準分數;較穩妥的做法,是把它視為一條值得追蹤的研究路線,再到論文中查看完整實驗細節。