RealICU 是一個用來評估大型語言模型在深切治療部情境下表現的基準。重點不在於AI有沒有照抄以往醫生做過的決定,而是看它面對長時間、資訊密集又持續變化的病人資料時,能否作出較接近臨床正確性的判斷。
如果你對醫療人工智能有興趣,RealICU-Bench 值得留意。它聚焦深切治療部入面又長又密集的病人資料,目的唔係叫模型照抄過往醫生做法,而係測試模型面對完整病程時,能否作出更合理判斷。
這個項目針對一個很實際的問題:ICU 決策往往要在高壓下,快速整合大量檢驗、監測和病程資訊。現有不少評估方法把歷史醫療行為當作標準答案,但原始決策當時可能資訊未齊全,因此未必最理想;RealICU 改用事後回顧整個病人歷程的標註方式,嘗試更公平地評估AI推理能力。
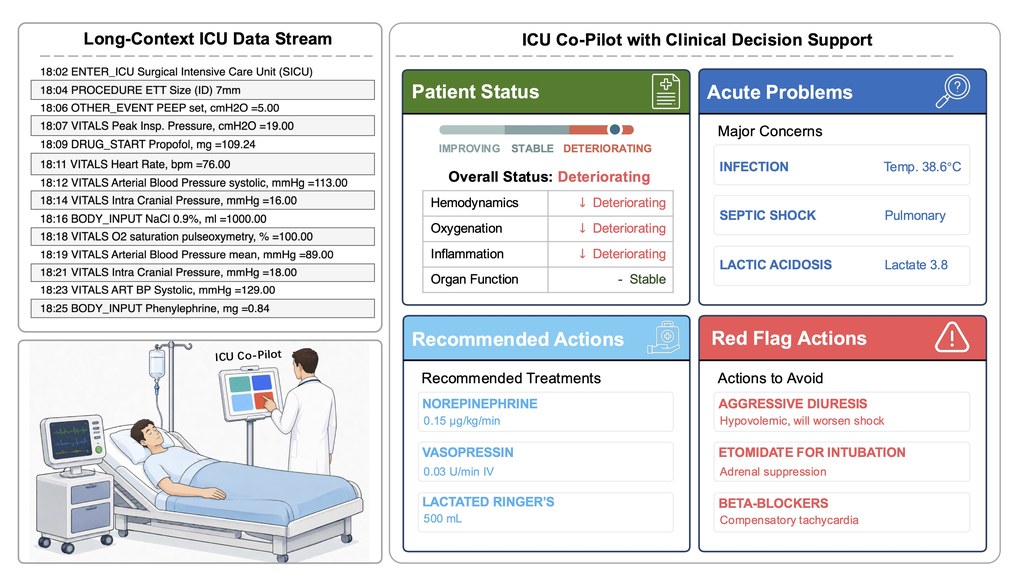
如果你想了解或使用這個項目,最適合由它定義的四類任務入手:病人目前情況、急性問題、建議處置,以及需要避免的危險行動。網站亦提供論文與程式碼入口,而資料集顯示仍有部分內容即將推出;若你是研究者,可先用 RealICU-Gold 和 RealICU-Scale 的設計思路,理解其評估框架。
- 由超過30位臨床醫生共同界定核心任務
- 包含 930 個醫生共識樣本,以及 11,862 個大規模評估視窗
- 引入經醫生驗證的 LLM 評估器作大規模標註
- 提出 ICU-Evo,以結構化記憶研究長時序推理
- 發現前沿模型存在召回與安全之間的取捨,以及錨定偏差
這個項目的創新之處,在於它把評估焦點由「像不像醫生以前做過的事」轉向「是否真正理解病情演變」。另外,ICU-Evo 用多種結構化記憶整理臨床上下文,較貼近醫生思考方式;不過作者亦明確指出,這類方法雖有助長程推理,仍不足以保證安全。
整體而言,RealICU 特別適合醫療AI研究者、醫院創新團隊,以及關注高風險場景AI安全的人士。從現有結果看,這不是一個宣稱模型已可直接臨床部署的項目,而是一個更嚴謹的測試場,幫助大家看清AI在真實重症決策支援中的能力與限制。
| 層級 | 作用 | 規模 | 標註方式 |
|---|---|---|---|
| RealICU | 整體 benchmark | 全部框架 | 包含 Gold 和 Scale 兩部分 |
| RealICU-Gold | 高品質基準集 | 930 windows / 94 patients | 醫師共識標註 |
| RealICU-Scale | 大規模延伸集 | 11,862 windows | Oracle 自動擴展標註 |
在 RealICU-Gold 上,Gemini-3.1-pro + ICU-Evo 達到 Patient Status 0.459、Action Recommendation Recall@5 0.534;同時,structured memory 雖然提升了長程推理,但仍然沒有徹底解決安全失敗和 anchoring bias. 也就是說,ICU-Evo 是“更好的 memory-based agent”,但不是把 RealICU 這個 benchmark 作為最終方案。
RealICU
├─ RealICU-Gold
│ └─ 930 個 window,來自 94 個 ICU stays
│ └─ 由多位 ICU 醫師做 hindsight consensus 標註
└─ RealICU-Scale
└─ 11,862 個 window
└─ 用 Oracle(醫師驗證過的 LLM hindsight evaluator)自動擴展標註