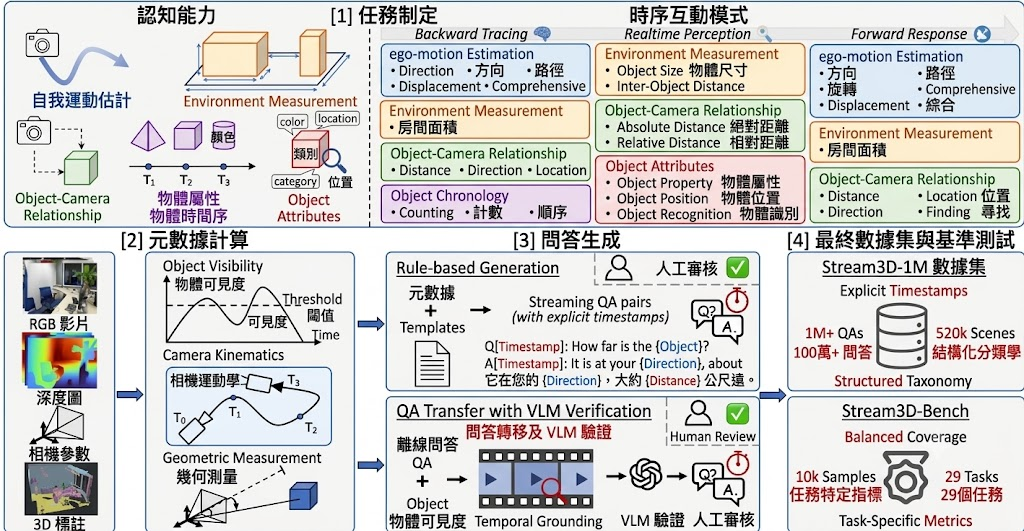
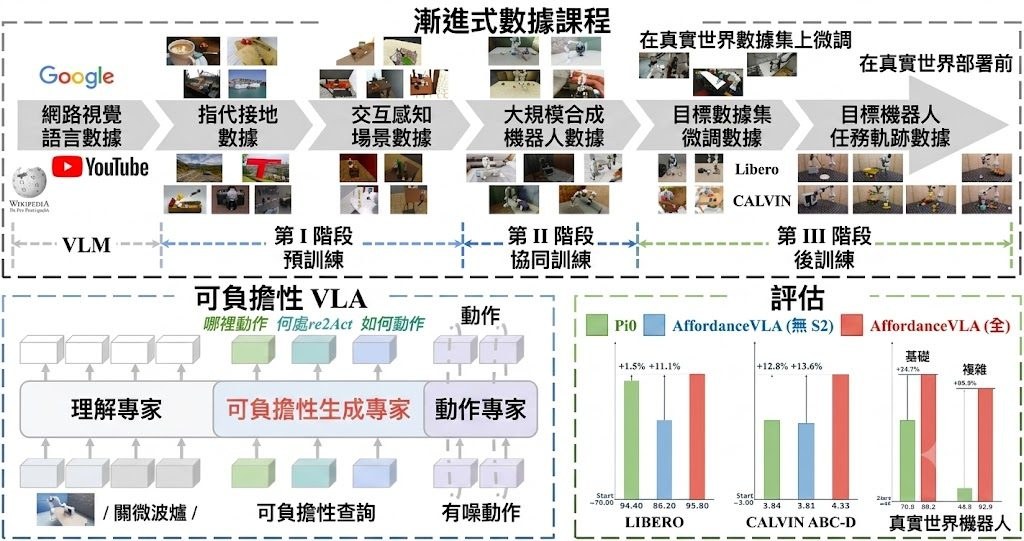
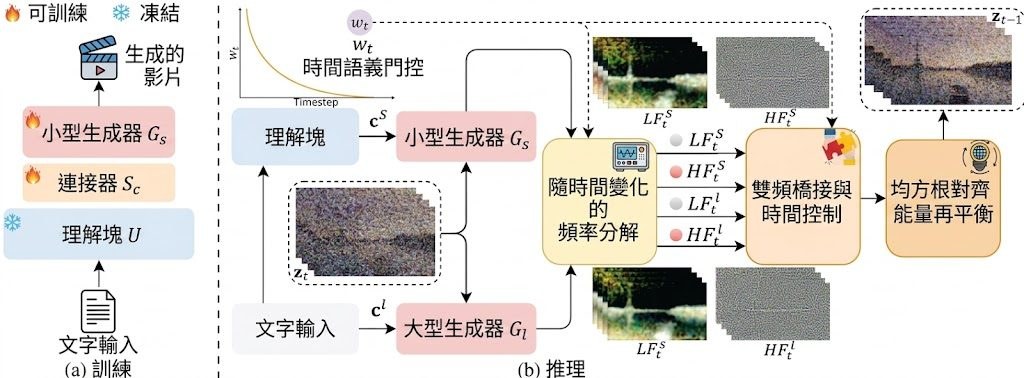
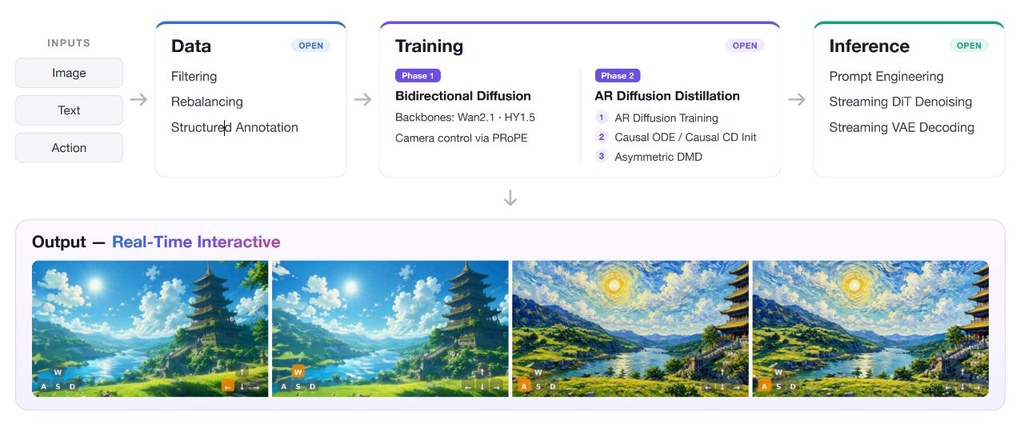
DomainShuttle 是一個以 Wan2.2-T2V-A14B 為基底的 subject-driven text-to-video(主體驅動文字轉影片)框架,目標是讓用戶提供一張參考圖後,能在不同視覺風格與場景中維持同一角色的身份一致性。過去的 subject-driven 方法多在 in-domain(與訓練資料同域)下能保留主體細節,但一旦跨域到風格差異大的場景,主體往往走樣或失去身份特徵;DomainShuttle 把參考特徵與影片特徵解耦,並引入 domain attribute 建模與 intrinsic subject representation,試圖兼顧 in-domain fidelity 與 cross-domain editability。
開發團隊來自香港科技大學 C4G 實驗室,作者群包括 Nan Chen、Yiyang Cai、Rongchang Xie、Junwen Pan、Cheng Chen、Weinan Jia、Zhuowei Chen、Wen Zhou(項目負責人)、Zhenbang Sun 以及通訊作者 Wenhan Luo。等貢獻作者共同發表技術報告,並同時釋出 14B 規模的非官方權重與推理代碼。
先以 conda 建立 Python 3.10 環境並安裝 PyTorch 2.5.1(CUDA 12.4),接著執行 build_env_conda.sh。模型準備分兩步:先用 huggingface-cli 下載 Wan-AI 的 Wan2.2-T2V-A14B 作為基底模型,再下載 CNcreator0331/DomainShuttle_weight,最後將 VAE、configuration.json 等檔案移入指定的 ./models/Diffusion_Transformers/Wan2.2-DomainShuttle-A14B/ 目錄。原始資料未提供完整推論指令片段,相關細節需參考技術報告與項目頁面的後續說明。
從示範結果看,DomainShuttle 能在寫實人物、動漫風、Ghibli 風、3D 動畫風等不同域之間切換,同時保留臉部與服飾特徵,跨域 personalisation 效果明顯。適合短片創作、角色 IP 化、廣告分鏡與動畫預覽等需要「同一角色穿梭多場景」的團隊。需注意目前釋出的是非官方實作,且依賴 14B 規模的基座模型,部署對顯存要求較高。
重點摘要:
- 類型:subject-driven text-to-video 框架,建基於 Wan2.2-T2V-A14B
- 開發團隊:香港科技大學 C4G 實驗室,Wen Luo 為通訊作者
- 核心設計:解耦參考與影片特徵、加入 domain attribute 與 intrinsic subject representation
- 與同類差異:強調 cross-domain editability,補足過往方法跨域走樣的缺陷
- 資源:已釋出 14B 權重、技術報告與推理代碼,需 CUDA 12.4 環境
GitHub: https://github.com/HKUST-C4G/DomainShuttle
項目主頁: https://cn-makers.github.io/DomainShuttle/
模型: https://huggingface.co/CNcreator0331/DomainShuttle_weight