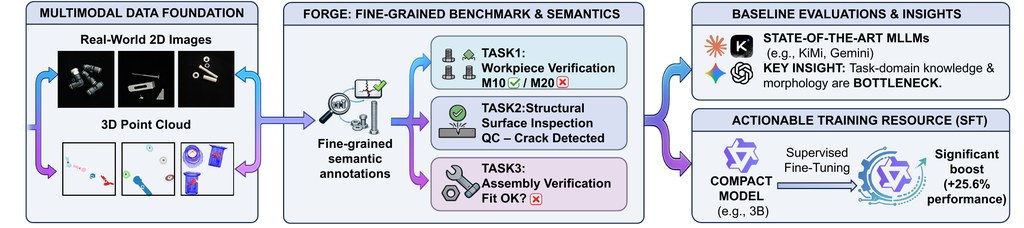
FORGE 提出了一個全面的評估框架,專門針對視覺語言模型(VLMs)在工業製造異常檢測中的應用。這個工具對於希望評估和改進 VLMs 在實際製造場景中表現的研究人員、工程師和 AI 專業人士特別有價值。該框架涵蓋了三個核心任務和基礎消融研究,提供了一種多維度的方法來理解 VLMs 在檢測異常(如錯誤模型、額外零件和缺失組件)方面的能力和限制。
在深入研究 FORGE 時,用戶應首先專注於理解三個主要任務:錯誤模型檢測、異常分類和額外/錯誤零件檢測。這些任務旨在模擬製造環境中面對的實際挑戰,使用照片和渲染圖像。基礎消融研究進一步探討了空間基礎和跨圖像零件匹配,提供了對 VLMs 空間推理能力的洞察。
在實踐中,FORGE 通過利用多種評估設置(包括零樣本、少樣本和上下文學習(ICL))來運作。用戶可以通過 YAML 文件配置這些設置,這些文件控制所有評估參數,如模型名稱、溫度和最大令牌數。這種靈活性使研究人員能夠根據自己的特定需求和假設量身定製評估過程。該框架支持多種後端,如 OpenRouter、OpenAI、Anthropic 和 Google,使用戶能夠實驗不同的 VLMs 並觀察其性能變化。
最能從 FORGE 中受益的是那些參與製造業 AI 解決方案開發和部署的人士。通過提供標準化的基準,FORGE 幫助這些專業人士識別各種 VLMs 的優缺點,促進在模型選擇和整合方面的明智決策。此外,詳細的輸出文件,包括緊湊結果、帶有原始 API 訊息的完整結果和執行日誌,為分析和報告提供了寶貴的數據。
然而,也有一些權衡需要考慮。框架的複雜性可能對新手構成學習曲線,需要對 VLMs 和異常檢測原理有紮實的理解。此外,運行廣泛評估所需的計算資源可能相當龐大,特別是在處理大型數據集和多種評估設置時。用戶還應當小心數據集中的潛在偏見和評估任務的限制,這些可能無法完全捕捉到實際製造異常的所有方面。
為了充分利用 FORGE,用戶應從探索存儲庫中提供的示例 YAML 配置文件開始。這些文件作為設置和運行評估的實踐指南。熟悉不同任務及其特定要求也是有益的,因為這些知識有助於設計有效的評估策略。此外,利用基礎消融研究可以提供對 VLMs 空間推理能力的更深洞察,這對於涉及零件匹配和空間基礎的任務至關重要。
FORGE 是一個強大的工具,用於評估視覺語言模型在製造異常檢測中的應用。它提供了一種結構化的評估模型性能的方法,涵蓋各種任務和設置,使希望在工業環境中增強 AI 應用的研究人員和工程師受益。儘管存在複雜性和資源需求,但框架的靈活性和全面的輸出使其成為推進製造業 AI 領域的寶貴資產。
City University of Hong Kong | HKUST (Guangzhou) | CUHK (Shenzhen)