不少視覺題目唔係靠一眼辨認,而係要沿住線追、逐區域數、一步步核對先答得到;ActiveVision 正正針對呢種落差而來。作為一個 benchmark,它集中測試 iterative visual reasoning,處理的是模型看得到畫面,但未必能持續整理觀察過程的問題。
現有多模態模型常見做法是對單張圖作一次性判讀,再配合 chain-of-thought 直接作答;作者認為這種 single-glance 範式,對需要反覆掃描、追蹤順序與維持中間狀態的題型特別吃力。ActiveVision 因此設計了 17 個任務,並用 deterministic program 生成場景,再以 photorealistic 方式重繪,令畫面自然之餘仍保留可驗證結構。
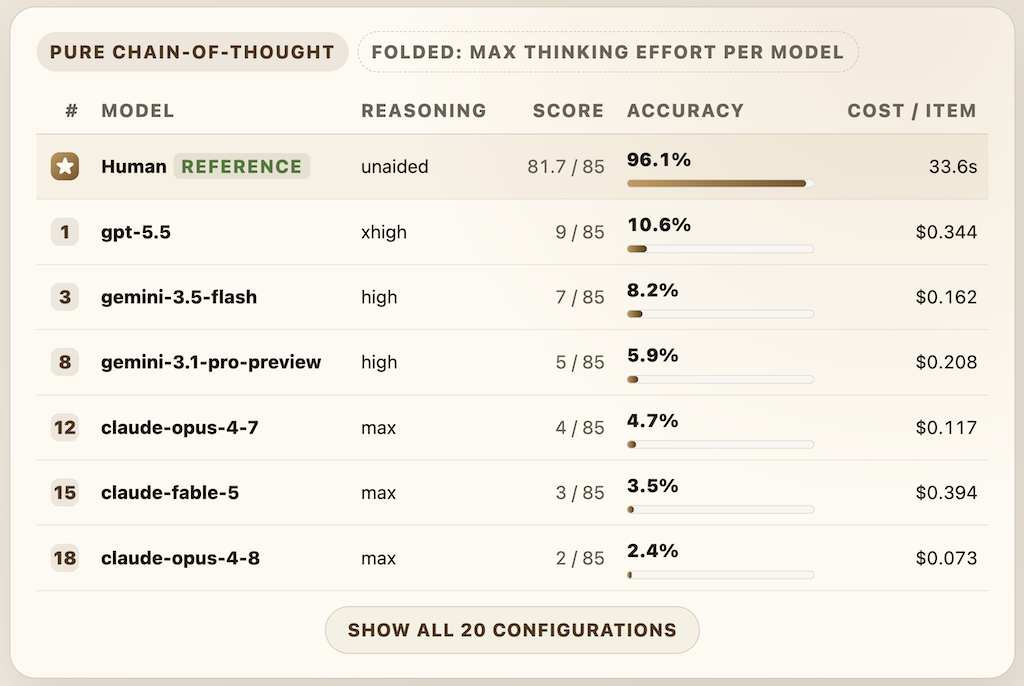
數字相當直接:人類表現為 96.1%,前沿模型在官方無工具評測下最高約 10.6%,差距接近 9 倍。網站亦列出 agent 版本的 tool-use ablation,像 Claude Code 與 Codex 接入工具後,分數明顯高過純 chain-of-thought,表示問題未必只是「看不懂圖」,而是缺少可逐步外化與操作的解題流程。
- 收錄 17 個任務,重點放在 distributed scanning 與 sequential traversal 一類逐步觀察題
- 官方評測涵蓋 Claude、GPT、Gemini,亦提供 agent ablation 腳本
- 數據集可經 Hugging Face 下載,評測程式以 Python 為主
- 同一靜態圖片也能迫使模型做多步推理,唔靠影片輸入撐起難度
整個 GitHub 項目比較像研究與評測基建,而唔係即用型產品:你需要先下載數據集、配置對應供應商 API,然後用 repo 內的 eval 腳本跑結果。對做多模態模型評測、Agentic 工作流、或者想驗證 Computer-use agents、CUAs 式外部工具協作價值的團隊,它提供了一個很尖銳的檢查點:模型是否真的會「觀察」,還是只會對影像作高階猜測。