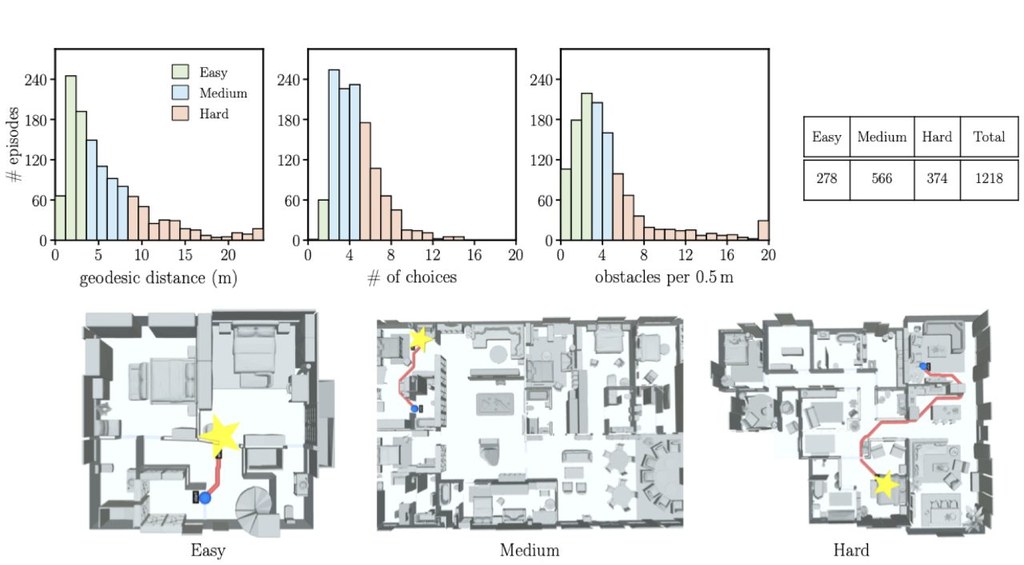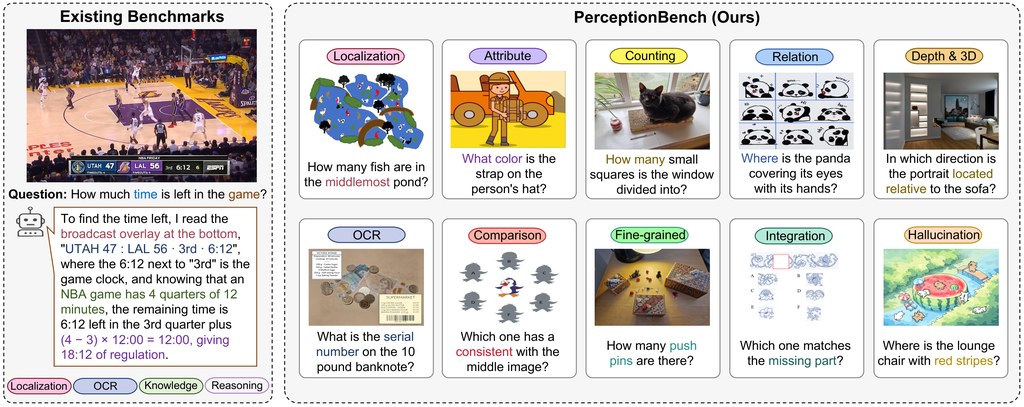
不少 Multimodal Large Language Models(MLLMs)表面上回答完整,但錯誤未必來自推理,往往早在「看圖」那一步已經出現。PerceptionBench 就是一個評測資料集兼 benchmark,專門把視覺感知拆成最細單元,檢查模型究竟係讀錯字、看漏關係,還是出現 perception-related hallucination(Hallu)。
它的價值,在於不再用一個總分掩蓋問題。團隊先分析 42 個現有 benchmarks 的失敗案例,再整理出一套錯誤分類,當中視覺感知分支包含十種 atomic perceptual capabilities,之後用這個框架建立 3,000 條經驗證題目,每題只測一種能力,答案亦刻意保持簡短而明確,盡量避免把推理或背景知識混入結果。
對做模型評估、資料標註或多模態產品調校的人來說,這個項目最有用的地方,是你可以更早定位問題源頭。它不是教你部署模型的工具,而是用來比較模型能力輪廓的尺;資料已放上 Hugging Face,程式碼亦公開,較適合拿來跑 benchmark、重現論文結果,或者把自家模型放入同一套題目做橫向比較。
- 以 3,000 條 verified questions 測十種 atomic visual perception 能力
- 題目刻意隔離單一能力,減少推理與知識干擾
- 共評測 16 個 frontier MLLMs,使用統一 prompts
- 沒有模型準確率超過 60%,Hallu 表現平均最弱
- 相近總分之下,不同模型的能力分佈可以差很遠
所有題目都採用開放式短答案,再由 GPT-oss-120B 依參考答案判分,官方指它與人工審核在 300 個樣本上的一致率達 99.7%。這類設計未必等同真實產品場景,但很適合做能力層面的診斷;當你想知道模型到底「唔識答」還是「睇錯圖」,PerceptionBench 提供的資訊比一般綜合排行榜更有分析價值。