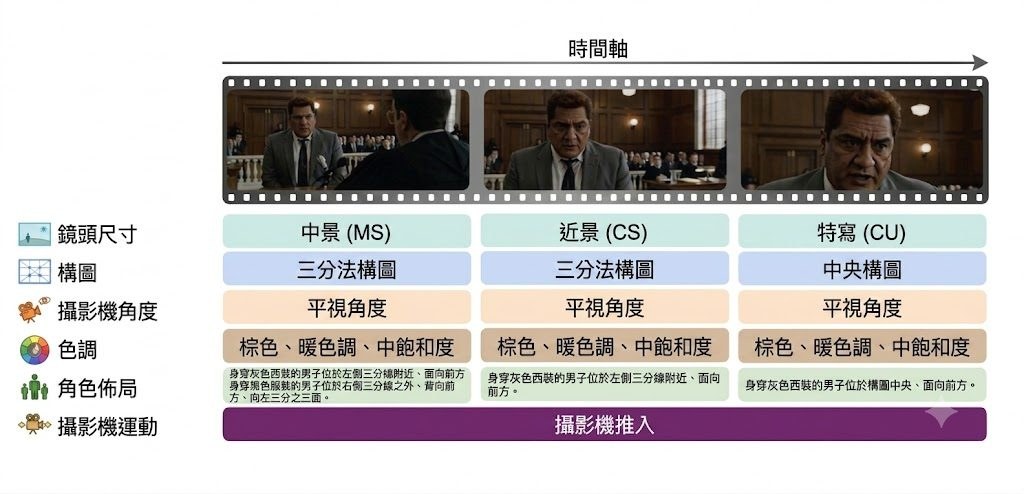
只做臉部外殼,很多時已經唔夠用;去到動畫、重建同生成式影像控制,眼球、口腔同頭部姿態一旦分離得唔好,效果就會即刻穿崩。google/GNM 目前先開放的 GNM Head,屬於3D parametric statistical human model 項目,焦點是用更完整的人頭幾何表示,處理傳統 3D Morphable Models (3DMMs) 對內部 anatomy 覆蓋不足的問題。
這個項目的取向很鮮明:不只是追求一個可調參的人臉網格,而是把 head、face、neck、eyeballs、teeth、tongue 放進同一個生成式人體測量框架。作者在技術報告指出,現有公開模型多數只覆蓋外部幾何,亦容易受限於低保真掃描資料;GNM 則結合高解析 3D scans 與 anatomy-specific artist-made samples,並加入 ocular 同 intra-oral specialized sub-models,目的就是改善幾何品質同可控性之間的取捨。
現有儲存庫較像一個生態系入口,而唔係即開即用的單一應用程式。README 清楚列出 GNM Head 已提供 NumPy、JAX、PyTorch、TensorFlow 多後端支援,亦有 Linux、macOS、Windows 的 CI;但目前公開資訊以模型與技術報告為主,未見到很完整的產品化操作流程說明,所以較適合研究、角色生成、數碼人、3D 視覺或生成式影像控制團隊按其子目錄文件逐步接入。
- 補足傳統 3DMM 常見缺口:不只外形,連眼球、牙齒、舌頭都可控
- GNM Head 強調 identity、expressions、head pose 的 disentangled control
- 同時支援 NumPy、JAX、PyTorch、TensorFlow,方便接去不同研究流程
- 技術報告聲稱在 fitting target 3D face scans 達到 SotA 表現,但具體指標仍要回看原報告
它最吸引人的地方,在於把「可生成、可擬合、可作條件控制」三條路線拉到同一個模型家族內。現階段公開內容仍以 GNM Ecosystem 的起步版本為主,想拿來做完整 production pipeline,仍要自己判斷與現有重建、動畫或生成系統的整合成本;但作為高保真人頭 3DMM 的新基礎,這個項目的研究價值同延展空間都相當高。