不少簡報生成工具仍然走 one-shot source-to-slides conversion:丟一份材料進去,整份投影片一次生成,之後每次修改又大範圍重做。MemSlides 把問題改寫成 stateful authoring process,核心不是單次輸出,而是記住你是誰、這一輪想改甚麼,以及過往哪些工具操作較可靠。
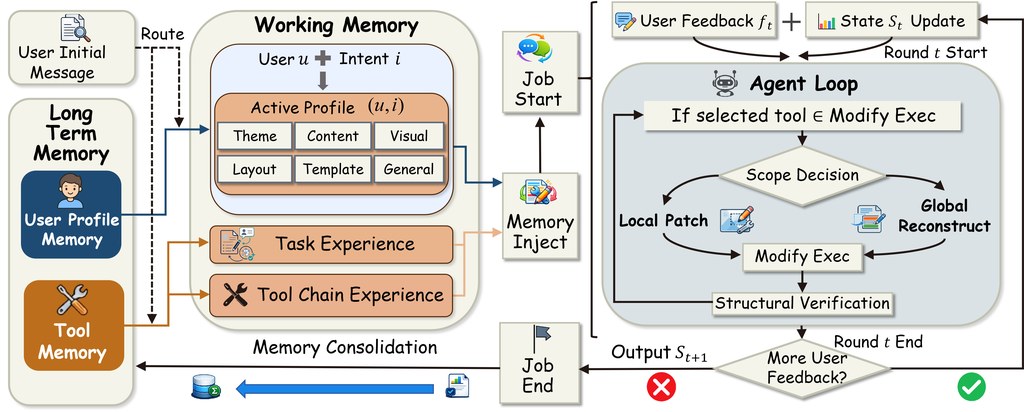
這是一個 Agent Framework,目標是解決 personalized slide generation 與 multi-turn local revision 兩個常見痛點。它把記憶拆成 user profile memory、working memory、tool memory:前者保存跨工作重覆出現的偏好,中段記住當前簡報的限制與暫時要求,後者則保留工具鏈執行經驗,方便之後做相似修改時少走彎路。
跟同類做法相比,最需要留意的是它不主張每次收到新意見就重生整副 deck,而是做 scoped slide-local revision,只更新受影響的最小區域。這種取向的好處是修改更穩定,較易保留原本好的內容;代價是整體品質會依賴記憶管理與局部編輯判斷是否準確。
從倉庫資訊看,這個項目較適合研究 presentation agents、企業內部簡報自動化,或要反覆為不同角色產出版本的團隊。倉庫亦提供 Docker Hub、網站、示範影片與論文連結,理解方式可先看 demo,再決定用容器部署還是按 Python 3.11 與 Node 20 的環境自行搭建;不過公開資訊未見完整量化基準,現階段較像研究型框架,而非已標準化的產品方案。
- 把簡報生成由一次性輸出改成有狀態的寫作流程
- 分層記憶是重點:user profile memory、working memory、tool memory
- 修改時傾向局部修補,不是整份重生成
- 適合需要 persona-aware 內容、反覆修訂、多人協作的情境
- 相關元素包括 presentation agents、multi-turn revision、localized editing、tool-chain execution