【AIGC实战课 99】全面掌控生成方向!LTX-2.3 IC-LORA 多重控制引导生成


ClawKeeper 是 SafeAI-Lab-X 開發的開源專案,提供 OpenClaw 自主代理的全面即時安全框架。
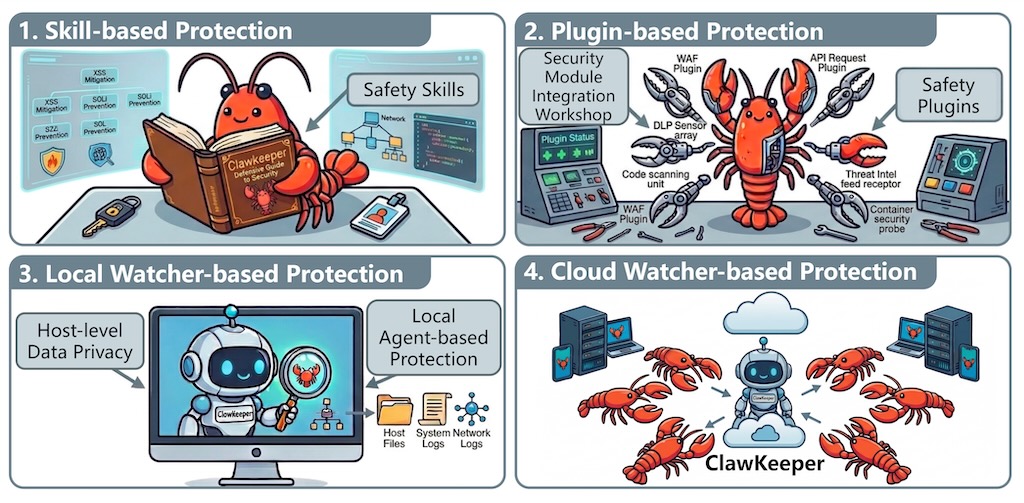
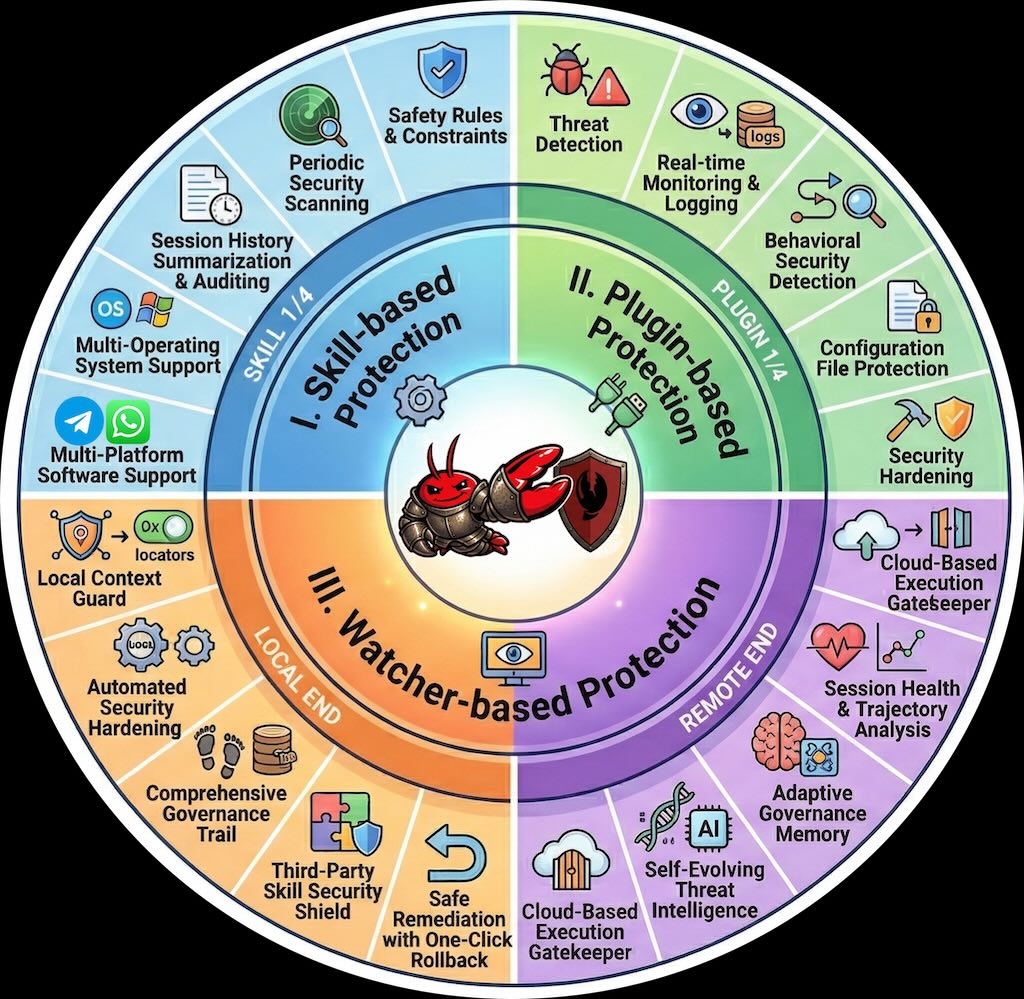
ClawKeeper 透過三層架構保護 OpenClaw 代理:技能層(指令級政策注入)、插件層(運行時執行與監控)、監視器層(獨立外部監督,可中斷高風險動作)。
它防範提示注入、憑證洩漏、代碼注入等威脅,並支援跨平台與雲端部署。

GStack 由 Y Combinator 總裁 Garry Tan 開發,已獲近 5 萬 GitHub 星標,提供 20+ 角色工具如 CEO 審核、工程經理和 QA。
安裝簡單,只需在 Claude Code 貼上指令,即可透過 /gstack 命令啟用辦公室會議、程式碼審核等流程。
適合 solo 開發者模擬矽谷團隊,基於 Tan 的創業經驗。
NousResearch 的 Hermes Agent 類似 OpenClaw,已有 12k+ 星標,具自改善迴圈,能從經驗產生技能並優化。
支援終端介面、多聊天 app(如 Telegram)、並行子代理和記憶遷移。
強調自主學習,適合想探索 OpenClaw 替代者的你。
Obra 的 Superpowers 插件給 Claude Code 超能力,已超 11 萬星標,聚焦 TDD(測試驅動開發)和工作樹平行化。
安裝只需 claude plugin install superpowers,即用 /s brainstorm 等命令規劃、執行和審核程式碼。
強調從腦storm 到部署的全流程,適合開發導向使用者。
Paperclip 旨在打造零人力公司,33k+ 星標,使用 Node.js 和 React UI 協調 AI 代理團隊追蹤目標、成本和工單。
如 CEO、CTO 等角色自動處理 issue,支援心跳排程和審計日誌,但作者警告不易立即獲利。
未來將加知識庫和 OpenClaw 整合,適合實驗自主業務。
Pulse of Motion 讓你在觀看影片時「感覺更舒服」,但看不到技術本身。目前很多生成影片(如 SVD、Pika 等)的動作時間常常跑偏,作者稱這種現象為 chronometric hallucination,也就是「看起來平滑但實際上時間尺度錯亂」。
現在很多生成模型會「時間錯亂」角色走路太快/太慢;手勢、動作和音效不搭;看起來動作很順,但「感覺怪怪的」。這套技術可以用來:調整生成模型的輸出(例如:自動快慢放或重採樣),讓影片「更像真實拍攝」,看起來更舒服。自動檢測影片的 真實時間尺度;
LumosX 是一個針對 個性化多主體視訊生成(personalized multi‑subject video generation)提出的框架,重點在:
簡單說:一樣可以做 text‑to‑video + ID conditioning,但對多個人物、每個人對應什麼屬性,控制得更精細、更一致「可控視訊生成」與「多主體個性化內容」場景,例如多角色劇本生成、廣告、虛擬試衣、多角色 VTuber 相容演出等。
TRIBE v2(Trimodal Brain Encoder)是一個多模態基礎模型,用於輸入一段影片、音訊或文字,然後輸出一個對應的「全腦神經活動圖」(約 7 萬個體素的 fMRI‑style 活動預測)。
它在 Algonauts 2025 獲獎架構上進一步提升,準確度約是上一代 2–3 倍,空間解析度提高約 70 倍,並支援跨受試者、跨語言、跨任務的 zero‑shot 預測。
可以當成一個「神經科學可視化工具」,用來研究。例如內容設計(影片、廣告、UI)如何觸發大腦特定區域(視覺皮層、語言區等)。又或者多模態 embedding 是否真的對齊人類大腦的處理路徑。

若你在做 RAG、多模態搜尋或 Brain‑AI 類實驗,可以拿這個 demo 來:比較不同 prompt/多模態輸入對「腦激活圖」的差異(例如:同一段文字用不同語氣、圖片風格重製)。
PrismAudio 是一個把視訊畫面轉成立體聲(stereo)音訊的 AI 模型框架,目標是在四個維度上同時優化:
作者的關鍵點是:現有模型通常把這些目標混在一個損失函數裡,會造成「目標互相干擾」(objective entanglement),而 PrismAudio 用 分解式 Chain‑of‑Thought(CoT)推理+多維度強化學習(RL) 來避免這個問題。
Matrix‑Game 3.0 是一個基於 Diffusion Transformer(DiT)的記憶增強世界模型,目標是做 720p 解析度、可達 40 FPS 的實時長序列互動視訊生成,用於第一人稱、第三人稱等遊戲/虛擬世界場景。它能根據滑鼠+鍵盤輸入一邊生成新畫面,一邊維持場景長時間的一致性(例如分鐘級序列),並可擴展到 2×14B 甚至 28B MoE 規模。
RealRestorer 是一個開源、通用型實拍圖像修復模型,目標是統一處理多種真實世界降級(blur、rain、low‑light、noise、haze 等),同時盡量保留原始場景結構與細節。