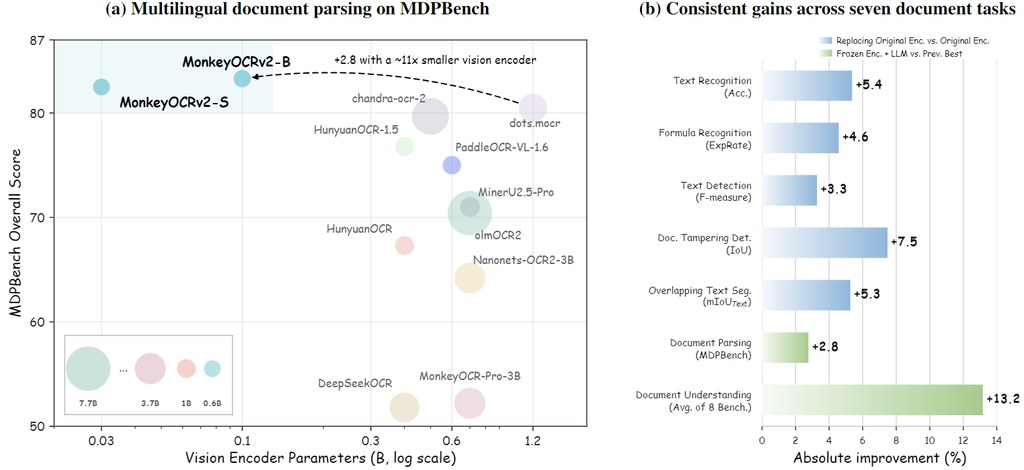
做3D同4D內容生成,最麻煩往往唔係單張畫面唔夠靚,而係鏡頭一轉、時間一推進,物件結構開始重複、錯位,角色仲會出現 jitter、identity flicker 同 structural drift。Hallo4D沿住呢個痛點出發,屬於一個研究型框架,重點唔係再訓練新模型,而係插入現有流程,幫3D與4D生成結果找出並修正時空不一致。
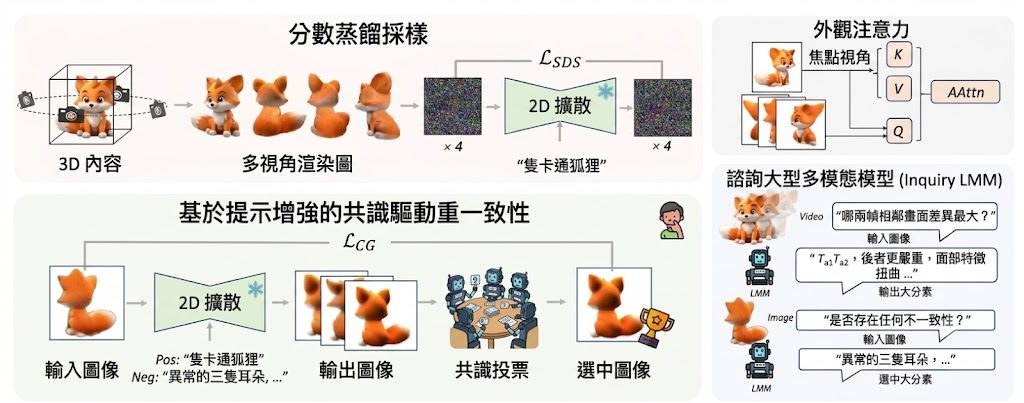
而家常見做法多數仍然依賴 2D diffusion-based supervision,但欠缺直接約束幾何一致性的機制,所以會出現 duplicated structures 同 misaligned geometry;去到4D,問題再擴大到時間軸。Hallo4D提出的是 generation-detection-correction 範式:先生成,再用 Large Multimodal Models(LMMs)從 multi-view、multi-frame renderings 判斷邊度出錯,之後以 image-space consistency optimization 做修正,並用 multi-model voting 揀較穩定的候選結果。
它不是跟同類方法鬥基礎生成能力,而是做一層 tuning-free、model-agnostic 的補救機制,聲稱毋須 retraining 或 architectural modification。代價亦很明顯,整個流程更依賴外部 LMM 推理、候選修正與投票判斷,較像高質後處理,而唔係最省算力的路線。
- 重點放在 spatio-temporal hallucination mitigation,不是直接取代原有 3D / 4D 生成模型
- 用 LMMs 檢查多視角、多幀輸出,再引導修正不一致位置
- 針對時間穩定性加入 optical flow 驅動的 keyframe sampling
- 以 CSEA、log-dynamic-range loss 同 union-of-frusta visibility pruning 處理曝光崩壞
目前較適合當作研究方法理解,而不是即開即用的產品工具。測試方式大致應是把它接到既有 Text-to-3D、Image-to-3D 或 4D pipeline,對比 baseline 與修正後結果,觀察多視角幾何、角色身份穩定度同曝光控制有無改善;頁面亦提供多組 visual comparisons,以及在 SV4D 的額外 4D 場景結果。
十分適合本身已經在做 3D / 4D 生成、又經常被跨視角穿崩同時序閃爍拖慢流程的研究團隊。相關脈絡亦值得一併看:Hallo3D主攻 multi-view-consistent 3D generation,Hallo4D則把範圍擴展到統一處理 3D + 4D 的時空一致性;量化表現,現有儲存庫文字未見完整指標表,判斷仍要以論文與項目頁面的可視化對比為主。