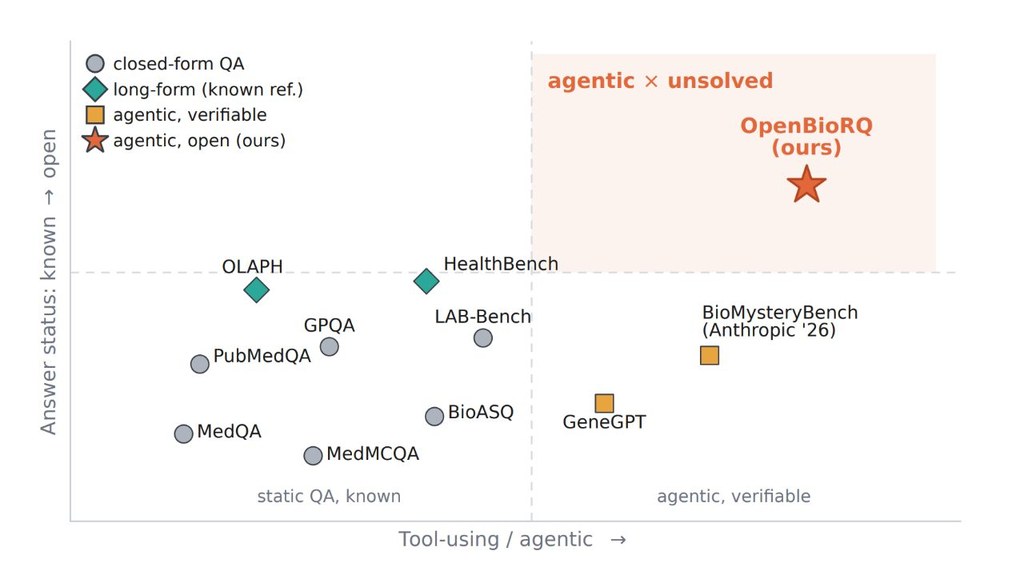
OpenBioRQ 是一個生物醫學基準資料集兼評測流程,聚焦於目前仍未解決的 biomedical / clinical research questions。它要解決的不是背答案能力,而是測試 LLMs 在 agentic tool use 情境下,能否自己找證據、正確引用文獻,並在沒有定論時保持 abstention。
現有 benchmark 多數採用固定答案 key 的問答範式,模型有機會靠記憶或線索反推標準答案,未必真的驗證過來源。OpenBioRQ 直接改用 retrieval-grounded openness:每條問題的 open_status 會用後續論文與 trial records 重新核對;難度也不是作者主觀標示,而是先讓強模型連工具一起跑,再用 pass/fail 結果界定哪些題目真的難。
項目的資料流程相當完整,從 crawl、extract、refine、dedup,到 status verification、contamination audit、agentic-eval 都有清楚分工。README 顯示它以 v3 的 12,553 題為基礎,另有 frozen core 作主要評測集;refine 步驟亦把問題整理成較自足的表述,自含性由 51.6% 提升到 85.4%,這對模型和人工評審都重要。
它和同類做法最大的分別,是把「引用可打開」與「引用真的支持答案」分開看。項目指出 agent citations 超過 99% 可以解析,但約 15.9% 其實連到錯誤論文;同時最難題組出現 agentic collapse,部分模型就算關掉工具,分數變化也不大,反映工具調用未必自然轉化成更好推理。
- 類型定位:屬於基準資料集加評測 pipeline,不是臨床決策系統
- 主要價值:檢查 evidence retrieval、faithful citation 與 abstention,而非考模型背誦
- 評測設計:用 per-question checklist rubrics 固定評分,inter-judge agreement 由 Spearman 0.35 升到 0.82
- 資料可靠性:core 657 與 expand 483 均報告 contamination hard 0%
- 相關模型:Google、Anthropic、OpenAI 三條獨立 lineage,以及 README 提到的 GLM-5.1、MiniLM-L6
受惠最大的會是做醫療研究助理、文獻檢索代理、醫學 AI 評測的團隊,而不是想直接拿去做診斷的機構。它目前更像一個研究基建項目:幫人看清楚模型在高不確定、無標準答案場景下,究竟是有能力找證據,還是只是在生成看似合理的回答。