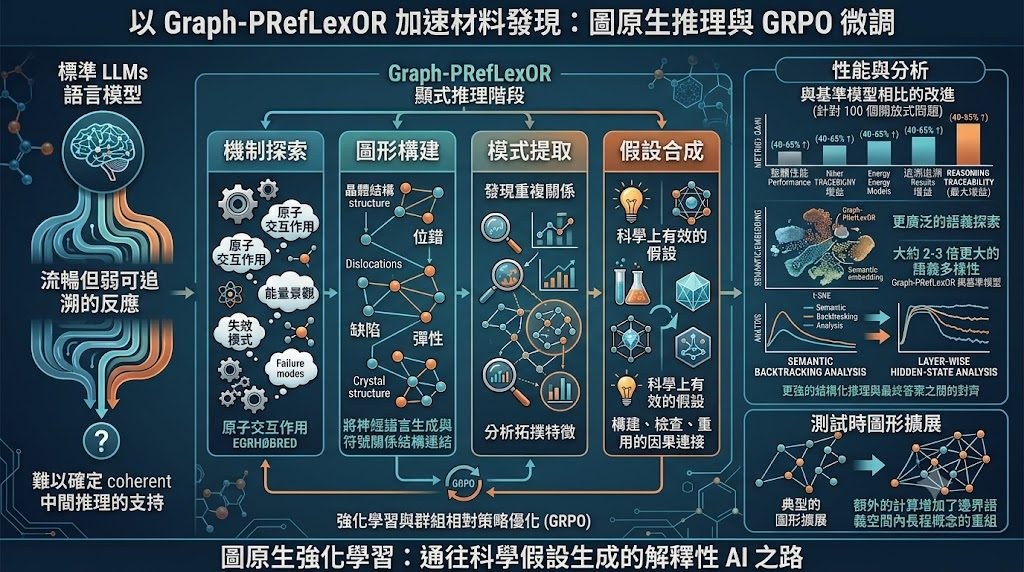
這是一個用來訓練語言模型的推理項目,核心屬於模型訓練流程兼研究原型。它要解決的問題,是模型回答問題時往往只輸出文字結論,推理結構難以檢查;Graph-GRPO 先要求模型把概念、關係與規律整理成 knowledge graph,再整合成答案。
現有做法多數依賴 chain-of-thought 或一般文字式 reasoning,把中間思路寫成自然語言。作者認為這種範式雖然靈活,但節點、因果、約束與抽象規律不易固定表示,因此提出 graph-native 的訓練方式:先用 ORPO(Odds Ratio Preference Optimization)或 SFT(Supervised Fine-Tuning)學格式,再用 Graph-GRPO 做強化學習,直接獎勵正確性、格式完整度與 graph utility。
項目的設計相當明確:節點類型限制為 entity、attribute、process、event、outcome、law、claim,關係亦只保留 12 種 verbs,並用 Pydantic 做結構化解析與 schema validation。這種取向的好處是輸出較易驗證,甚至能自動修補無效 graph;代價是表達自由度較低,未必適合非常開放、需要細膩語氣或鬆散聯想的回應。
部署與理解方式也算清楚,整個流程分成資料生成、run_orpo_graph 或 SFT 訓練,再進入 run_grpo_graph 強化階段,並以 LoRA 疊加在基礎模型上。README 亦提到可透過 OpenAI-compatible endpoint 驅動 ideation engine,把多輪生成的 graph_json 累積成可擴展知識圖,用於創意探索、問題延伸與比較不同前沿模型的表現。
- 適合想研究可追蹤推理、結構化回答與可驗證中間步驟的團隊
- 已釋出相關模型,基礎模型包括 Qwen-8B 與 Llama-3.2-3B-Instruct
- 獎勵設計公開列出 correctness、format、graph utility 三部分權重
- 亮點不在單純答得快,而在於把 reasoning 過程轉成可檢查的 graph object
在目前提供的內容中的性能不算完整,較明確的是訓練路徑、輸出結構與後續 ideation 用途,而 supporting context 另提到這條路線也延伸到 scientific hypothesis generation。整體來看,這個項目較適合研究型開發者、做 Agentic workflow 的團隊,以及想把 LLM 回答過程由黑盒文字轉成結構化證據鏈的人使用。