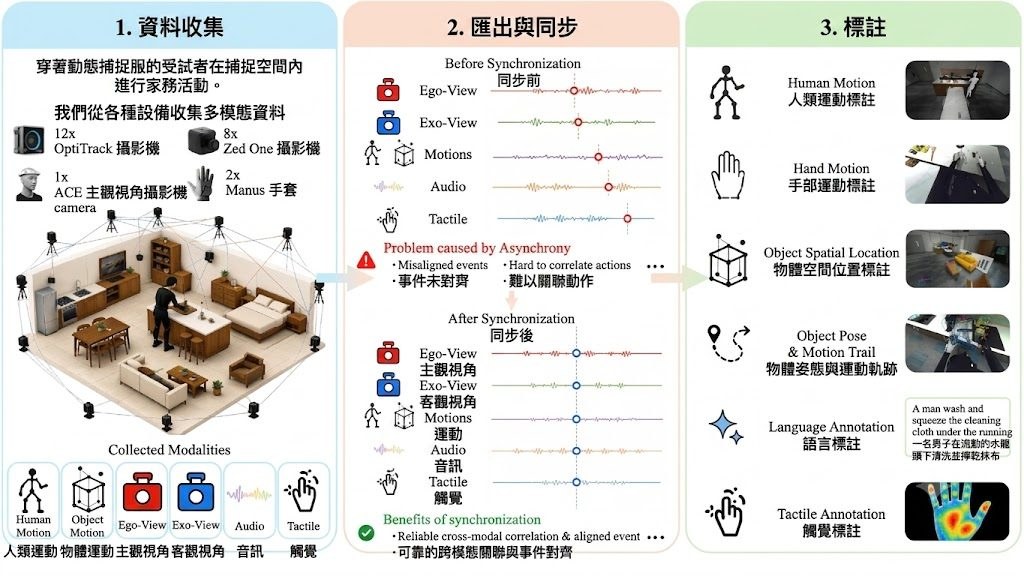
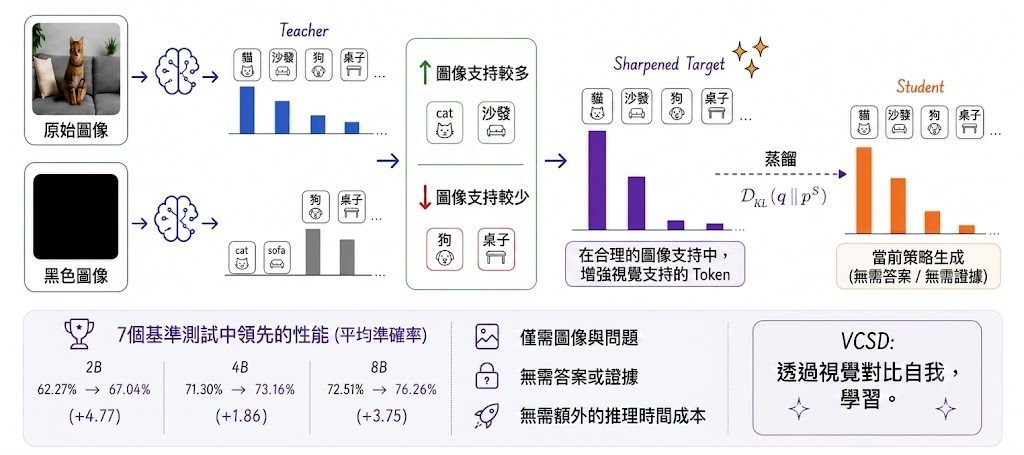
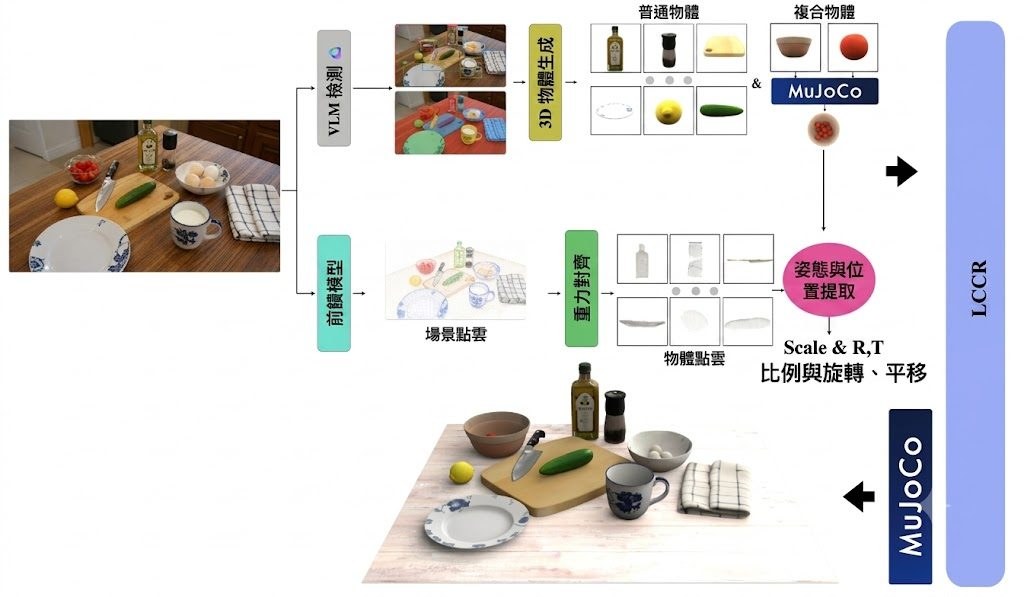
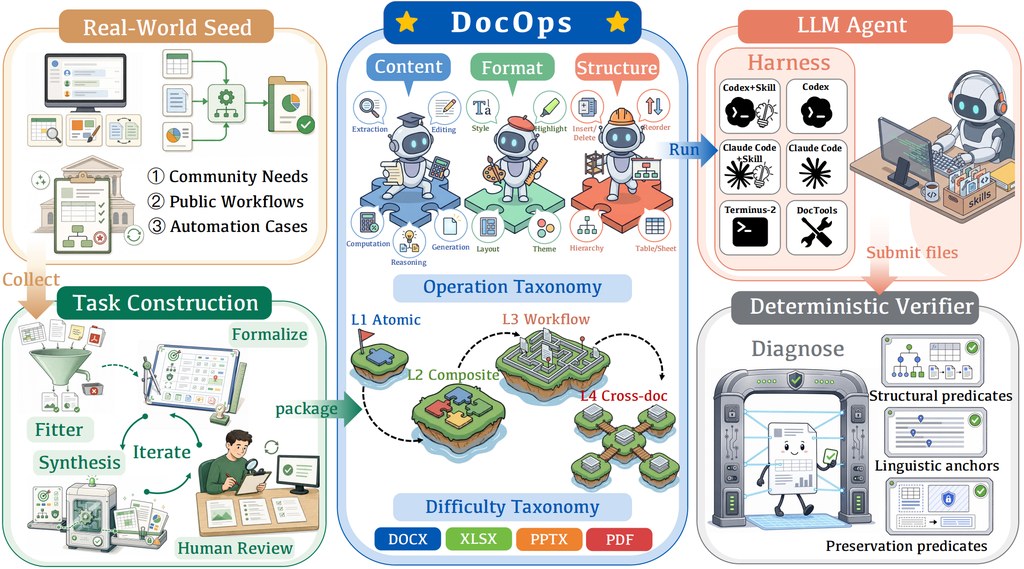
機械人控制最難受的地方,常常不是動作生成本身,而是模型一邊理解畫面、一邊預測未來場景時,推理成本高到難以閉環運作。GigaWorld-Policy-0.5屬於 World Action Model(WAM),重點是保留未來視覺動態對訓練的幫助,但在執行階段只解碼動作,減少為了生成未來影片而付出的額外開銷。
Xiaomi-Robotics-U0 屬於 world foundation model 路線,針對的正是這類 embodied synthesis 工作:一邊保留大型 image and video generation model 已學到的視覺知識,一邊補上機械人資料需要的可控性與一致性。
常見做法通常係用有限的機械人資料去微調 foundation model,但作者認為呢種範式容易犧牲大規模預訓練帶來的泛化能力。Xiaomi-Robotics-U0 改用 unified embodied synthesis 設計,把 text-to-image generation、image editing、embodied scene generation、embodied transfer 同 embodied video generation 放入同一個 38-billion-parameter multimodal autoregressive model 聯合優化,將 embodied generation 視為 foundation image and video generation 的延伸,而唔係另一條割裂的任務線。