最易理解 Gemini Spark 的方式,是把它看成一個會在背景持續運作的 Agentic AI 助手:你先交代目標,它再慢慢把零散工序接起來,處理那些花時間、又不想不停重複提示的工作。Google 已在香港推出這項服務,定位很清楚,就是幫用家把日常行政與資料整理自動化。
它接上的重點,不是單次問答,而是整段工作流。Gemini Spark 運行於 Google 的雲端基礎設施,能原生連接 Workspace 工具,例如 Gmail 和 Docs,毋須另外設定,就可以整理混亂的電郵往來、彙整行業消息、從舊文件抽資料做後續安排,甚至進行網上資料搜集、比較選項與完成預訂。
Google 提到,系統以 tasks、custom skills 和 schedules 這類機制去安排工作,讓用家用自然語言交代規則、例行事項與時間觸發條件,毋須寫程式。另一個分別在於,它不會因為你闔上手提電腦或鎖上手機就停下來,背景流程仍可繼續運作,較適合需要長時間跟進的文書與研究工作。
支援背景持續執行,不用反覆重新提示
可原生連接 Gmail、Docs 等 Workspace 工具
能處理資訊整理、排程準備、網上研究與預訂類工作
高風險動作前會先要求明確同意
控制權仍然留在用家手上。Google 表示,Gemini Spark 會按照用家指示運作,用家可決定何時啟用,以及容許它接觸哪些應用程式;遇到交易或發送電郵等高風險操作,系統亦會先徵求明確授權。現時香港由 Google AI Ultra 訂閱用家率先使用,Google AI Pro 用家的開放時間會在未來數星期逐步擴展。
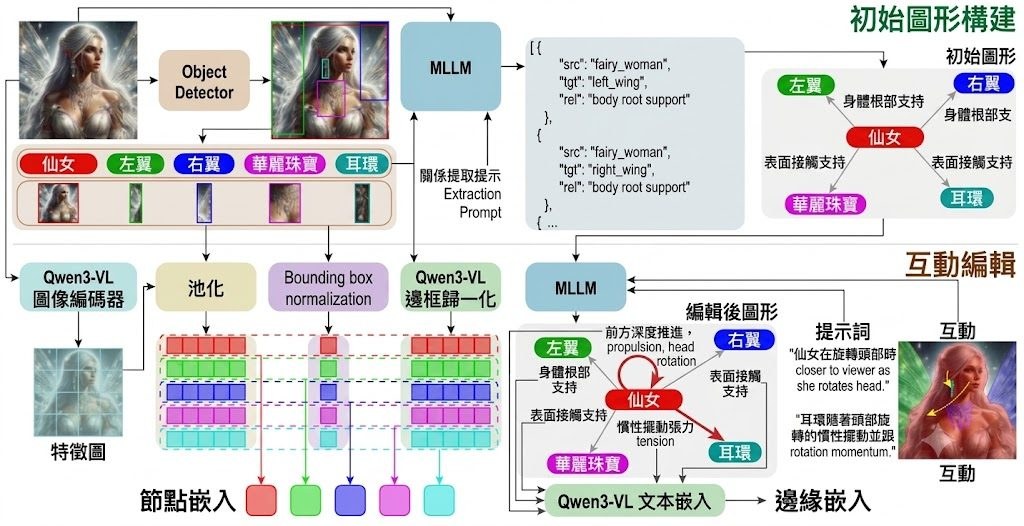
頁面沒有公開 base model 來源,也沒有說明訓練資料或評測指標,因此難以判斷它的整體品質,只能從架構面推測它把控制粒度從「逐幀文字描述」轉移到「節點拓樸」。使用 DiffusionPipeline.from_pretrained 配合 torch_dtype=torch.bfloat16,屬於現今影片擴散模型常見的省記憶體做法。
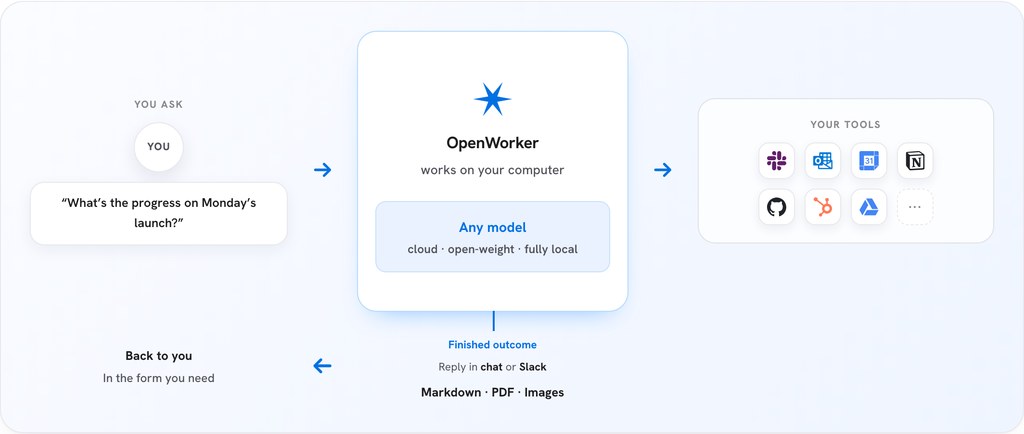
如果你係一個人或者小型團隊,想搵一個可以幫你「跑手」而唔係淨係「傾偈」嘅 AI 工具,又唔想將公司敏感資料送去閉源服務,OpenWorker 算係一個值得試嘅選擇。佢而家仲喺 open beta,官方表示會自動更新、不斷執吓啲 bugs,畀用家提交 issue。適合想認真將 AI 融入日常工作流、對私隱同可控性有要求嘅人。