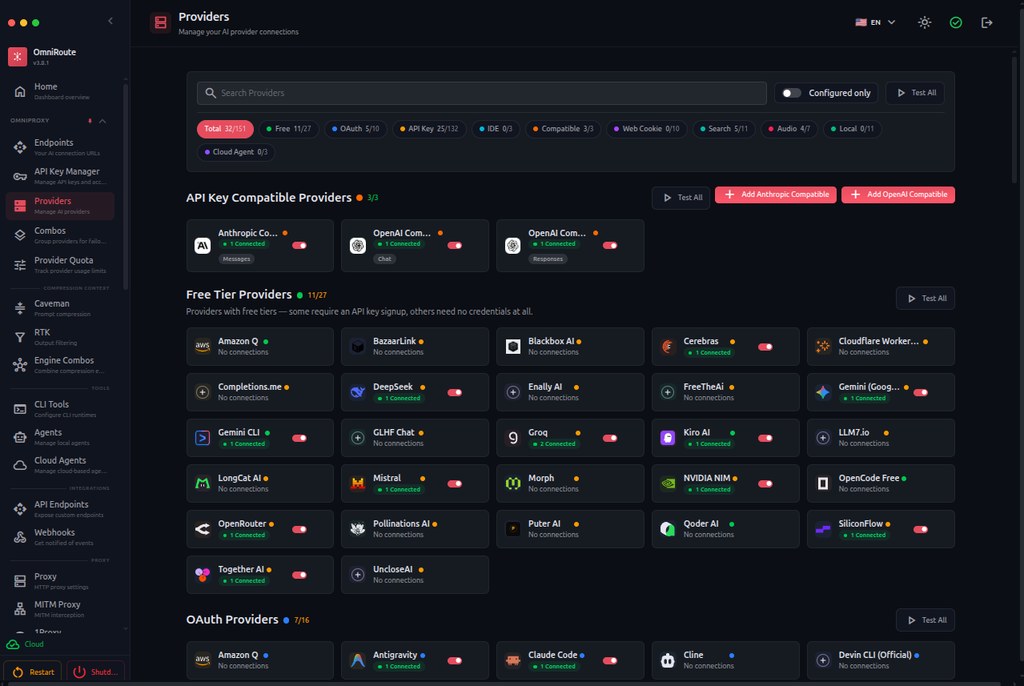
寫程式最怕做到一半先撞到配額上限,或者工具只綁死某一個模型。OmniRoute 把自己放在 AI gateway 呢個位置,直接處理多個 AI coding 工具同多個模型供應商之間的路由問題,重點唔係再造一個聊天介面,而係幫你維持請求可用、控制成本,並用 auto-fallback 減少中斷。
同類做法通常會主打單一 API 聚合,OmniRoute 的取向明顯更偏向「免費額度整合 + 路由策略 + 壓縮節流」。它聲稱可接到 237 個 providers,當中 90+ 提供 free tiers,並以 RTK + Caveman compression 把 token 消耗壓低 15% 至 95%。呢個方向的好處係對長提示、程式碼上下文同重複輸出較有幫助,但壓縮始終係取捨,所以它加咗 inflation guard,遇到壓縮後反而變長,就會送回原文。


你可以把它理解成放在 Claude Code、Codex、Cursor、Cline、Copilot、Antigravity 後面的中介層。部署後,工具經同一個 endpoint 出請求,再由 OmniRoute 分配到 Claude、GPT、Gemini 及其他供應商;README 也提到每個模型會列出本月已用與剩餘額度,並標示 provider terms,這點對團隊控管比較有用。
幾個值得留意的重點:
– 定位屬於工具 / 閘道型軟件,解決的是多模型切換、免費額度整合同配額中斷
– 支援 Claude Code、Codex、Cursor、Cline、Copilot、Antigravity,適合多工具並行的開發流程
– 以 documented free tokens/month 作招徠,現有資料提到穩定約 1.6B,首月可到 2.1B
– 內建 17 routing strategies,並加入 auto-fallback,減少單一 provider 失效帶來的停頓
– 壓縮模組已針對 German、French、Japanese、Chinese,以及 Gradle、.NET 輸出做過強化
受益最大的一般會係重度依賴 AI 編碼助手的個人開發者、細團隊,同想把成本壓到最低的實驗性項目。要留意的是,免費池本身受各 provider 條款影響,OmniRoute 雖然強調統計方式較透明,但效能與穩定性仍然建基於外部服務;它較像一個把資源調度做得更聰明的控制層,而唔係保證品質一致的模型平台。
![iRDM post-trains four-step FLUX.2 [klein] into a one-step generator at matched quality; GenEval and PickScore climb past](https://infernews.com/blog/wp-content/uploads/2026/07/teaser.jpg)