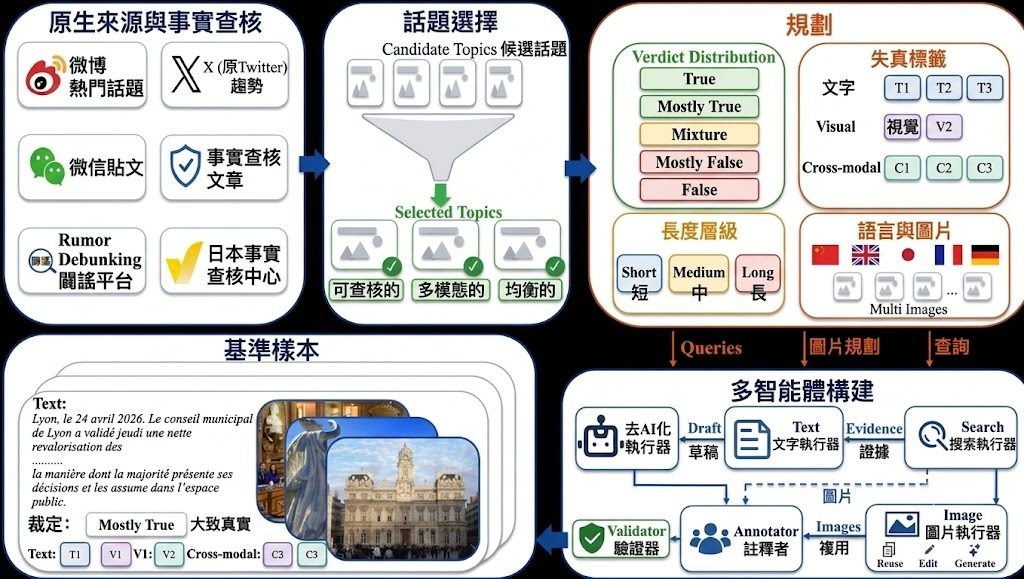
Semantic Browsing 是一篇發表於 ECCV 2026 的學術項目,由 Tel Aviv University 的 Sara Dorfman、Maya Vishnevsky、Omer Dahary、Or Patashnik 與 Daniel Cohen-Or 共同開發。它針對文字生成圖像模型在重複取樣時容易「語意塌縮」、產出過於雷同的問題,提出一套可控多樣性的工作流程。
這套方法的核心做法,是把多樣性從像素層級搬到文字層級。系統會先用多智能體(multi-agent)流程把使用者的提示擴寫成結構化的場景 JSON,記錄物件、屬性、互動與整體場景設定,再從中找出提示中未明確指定、但合理的變化軸心。每一次分支都對應一個明確的語意決定,例如角色、構圖或風格的差異,最終形成一棵可瀏覽的場景樹。
與一般常見做法相比,這個項目最值得留意的差異在於:變化不是來自隨機噪聲,而是來自可解讀的語意約束。樹狀結構讓使用者可以沿著特定分支往下探索,同時保留先前已固定的條件,方便在設計空間中做有意識的導覽。
重點摘要:
- 開發團隊:Tel Aviv University 的 Sara Dorfman、Maya Vishnevsky、Omer Dahary、Or Patashnik 與 Daniel Cohen-Or。
- 核心方法:以多智能體流程把提示展開為結構化 JSON 場景樹。
- 可控多樣性:每個分支對應一個明確的語意決定,而非隨機變化。
- 適用情境:概念設計、視覺探索、需要比較多個語意詮釋的創作流程。
- 目前狀態:程式碼尚未公開,僅釋出 arXiv 論文與項目頁。
使用方法詳細教學:
- 準備提示:先寫好一段文字提示,例如「A poster featuring animals」,提示中可以刻意留白部分細節,讓系統有空間展開變化。
- 進入項目頁:前往 Semantic Browsing 的官方網頁(saradorfman1.github.io/SemanticBrowsing-webpage/),等待互動介面載入。
- 送出提示並生成根節點:系統會先推論出一個初始場景詮釋,作為場景樹的根節點。
- 瀏覽與選擇變化軸心:介面會列出可變化的語意面向,例如角色、構圖、風格等,每個面向都會顯示目前值與替代選項。
- 展開分支:選定一個面向並挑選替代值後,系統會呼叫多智能體流程,在保留先前約束的前提下產生新的子節點與對應圖像。
- 沿著分支深入探索:可以重複步驟四與五,沿著感興趣的路徑繼續往下展開,逐步建立一棵專屬的設計樹。
- 匯出或記錄結果:若需要保留特定分支,可記下該節點的場景 JSON 或截圖,作為後續迭代或團隊溝通的依據。
由於程式碼尚未釋出,目前只能透過項目頁的示範介面體驗流程;待官方開源後,便能整合進 ComfyUI、Stable Diffusion 等本地生圖工作流。對於從事概念設計、視覺探索,或需要比較多個語意詮釋的創作者與研究人員來說,這套方法提供了一條比隨機抽樣更可控的探索路徑。
項目主頁: https://saradorfman1.github.io/SemanticBrowsing-webpage/