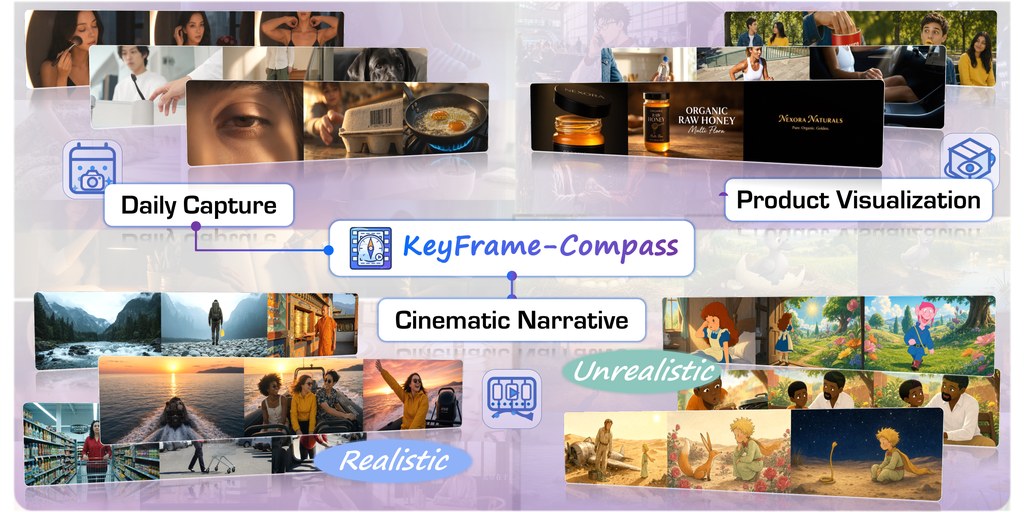
KeyFrame-Compass 是一個用來評測 keyframe-conditioned video generation 的基準項目,重點在於檢查模型能否同時跟住文字提示同一組按順序排列的 keyframes 生成影片。對做影片生成的人來說,這類測試最有價值的地方,是它不只看成片好不好看,還會追問畫面有沒有真係按要求出現、順序有沒有走樣。
這個項目把評測拆成兩層:一層看 keyframe execution,包括關鍵畫面存在、視覺還原、時間順序、定位、持續性同回應唯一性;另一層看 overall video quality,會用 evidence-grounded MLLM(Multimodal Large Language Model, MLLM)判斷,加上專門的感知模型去量度視覺質素、時間連貫性、指令遵從同音訊表現。這種分法比單純比對整體分數更清楚,因為它能分辨出模型係「畫得靚」定「跟得準」。
Xiaomi-Robotics-U0 屬於 world foundation model 路線,針對的正是這類 embodied synthesis 工作:一邊保留大型 image and video generation model 已學到的視覺知識,一邊補上機械人資料需要的可控性與一致性。
常見做法通常係用有限的機械人資料去微調 foundation model,但作者認為呢種範式容易犧牲大規模預訓練帶來的泛化能力。Xiaomi-Robotics-U0 改用 unified embodied synthesis 設計,把 text-to-image generation、image editing、embodied scene generation、embodied transfer 同 embodied video generation 放入同一個 38-billion-parameter multimodal autoregressive model 聯合優化,將 embodied generation 視為 foundation image and video generation 的延伸,而唔係另一條割裂的任務線。
同類方法很多會把功夫放在額外解碼器或多尺度結構,ReChannel的取向剛好相反:盡量把空間結構留在 DiT token field 內,最後只做通道重映射。這種設計夠輕,但取捨亦直接,現有儲存庫沒有完整 benchmark pipeline,姿態估計亦未放入最小示範,所以更適合用來理解方法潛力,而非直接拿來做嚴格橫向比較。
一邊輸入文字、一邊指定角色要去邊、幾時抬手或者身體要擺成咩姿勢,系統仍然可以即時生成自然動作;ARDY瞄準的正正是呢種互動式 3D human motion generation 場景。呢類能力對動畫、模擬同 humanoid robotics 都重要,因為傳統離線方法雖然控制精準,但速度未必跟得上互動需求;純即時方法又常常在語意理解、長距離目標同約束服從度上打折扣。
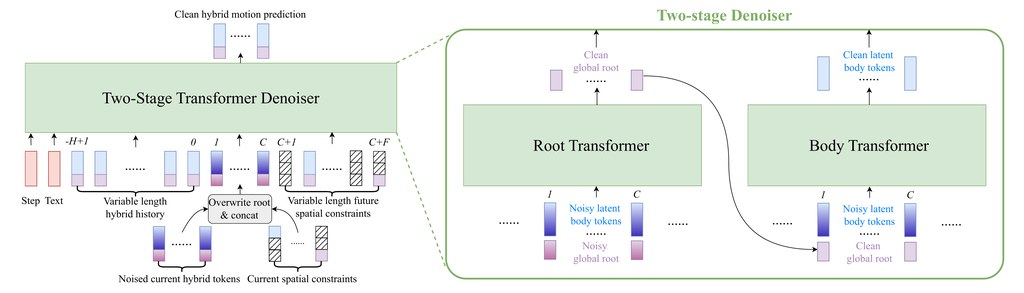
ARDY 採用 autoregressive diffusion model,同時配合 hybrid representation,把角色移動軌跡相關的 root features 同 latent body embedding 結合。咁樣做的用意很直接:一方面保留對路徑與朝向的明確控制,另一方面維持生成模型學習複雜全身動作時的效率與彈性。配合 two-stage autoregressive transformer denoiser,同一套框架可以處理 online text prompting,亦能接住較長時間範圍的 kinematic constraints。
當服務一出問題,最花時間往往唔係修復,而係先搵出 root cause analysis。呢篇內容聚焦企業 observability 點樣由 Generative AI 同 agentic AI 推進,令 AI agents 開始負責調查、整理線索同縮窄問題範圍,減少工程團隊喺大量 telemetry 同 log 之間來回切換。
文章提到,企業採用速度已經相當快,約 85% 組織正使用相關 AI 能力,而 Elastic 亦預期多數企業會喺兩年內,將 root cause analysis 更大程度交畀 AI agents。吸引力唔只在於自動化,而係將原本只有少數資深工程師先能處理的觀察與排障流程,慢慢變成更多團隊都可用的能力。
同常見做法相比,分別在於 AI agents 唔止回應查詢,仲會主動串連資料、追查異常脈絡,並以較接近調查員嘅方式處理 incident。呢種模式有機會改善資料存取門檻過高、工具過多同訊號過散嘅問題,但前提仍然係企業要信任結果,並保留人手覆核關鍵判斷。
重點放在 observability、incident investigation 同 root cause analysis
Generative AI 與 agentic AI 正由輔助查詢走向主動調查
約 85% 組織已採用相關 AI 能力,企業導入已進入加速期
目標係降低排障門檻,令更多團隊可直接理解系統狀態
對平台工程、SRE、DevOps 同需要處理大型分散式系統嘅團隊,呢種方向尤其有用。現階段最值得留意嘅唔係模型規格,而係 AI agents 能否喺真實企業環境中提供可追溯、可驗證、又足夠穩定嘅調查流程,呢點會直接影響大規模 adoption。
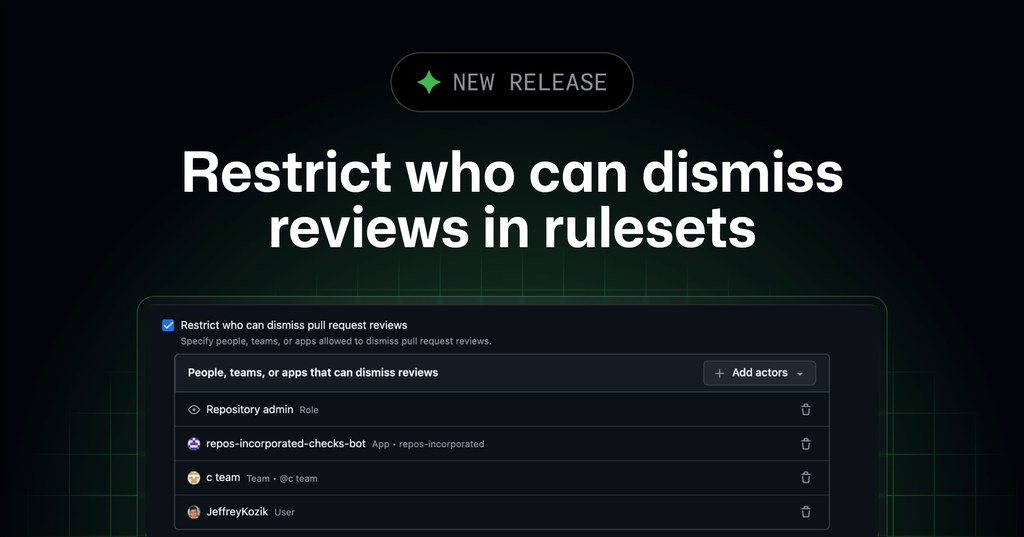
使用上做法唔複雜,只要打開 repository-level ruleset,啟用 Require a pull request before merging,再選擇 Restrict who can dismiss reviews 就可以。呢類更新唔係花巧功能,而係直接改善日常協作入面最常見嘅權限管理細節。