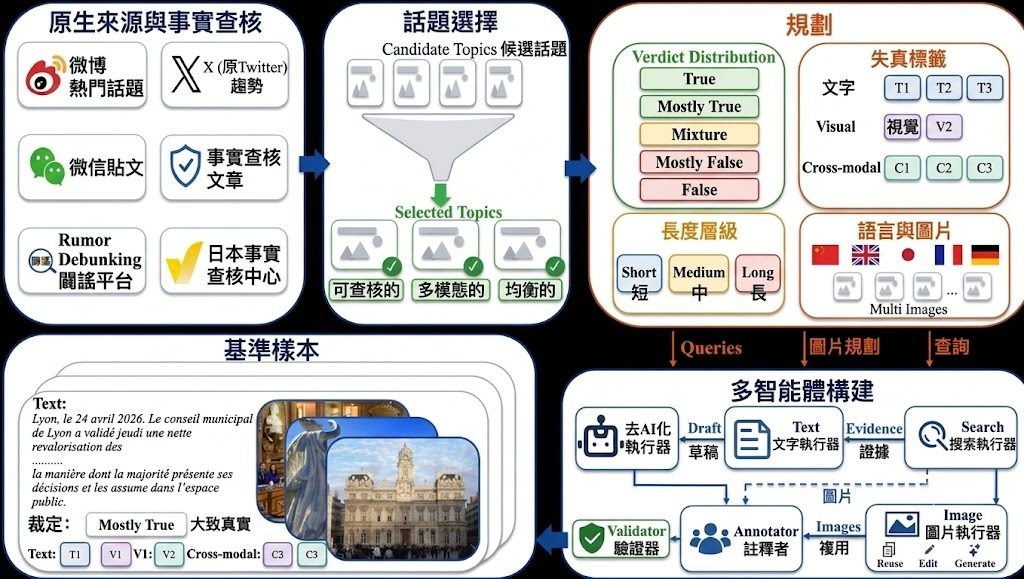
這是一個 Hugging Face Space,用來展示多個大型語言模型組合策略的分析結果,而不是可下載微調模型;頁面亦無提供 base model,因為它本身並非基於某個基礎模型微調而成。它主要回答一個很實際的問題:把多個 LLM 放入 routing、voting、cascade 或 mixture-of-agents(MoA)之後,是否真能穩定超越單一最佳模型。
核心結論圍繞 β = P(all wrong),即所有模型在同一題一起答錯的機率。文中指出,凡是輸出仍然只能選自成員模型答案的策略,理論上準確率上限就是 1 − β;常見的 pairwise error correlation ρ 即使相同,亦未必能反映 β,所以只看模型之間「錯得是否相似」並不足以估算可提升空間。
這個項目的價值,在於它把模型編排問題由「多加幾個模型會否更準」轉成「這些模型是否在不同題目上出錯」。作者用 67 個 frontier models、21 個供應商資料說明:就算是多樣化模型池,all-wrong tail 仍比單靠相關性模型估算更高;在 open-ended mathematics、execution-graded code 這類可檢查任務,多模型通常難以大幅勝過最強單模,除非有很強的 query-level routing signal。
- 這不是生成模型權重頁,沒有參數規模、context length、GGUF、mmproj 或量化檔案清單
- 不涉及 llama.cpp、Ollama、LM Studio 部署,亦無 Q4_K_M 一類量化建議
- 方法重點是用 Clopper–Pearson bound 先估計 β 上限,再判斷是否值得訓練 router
- 與 Self-MoA 類做法相比,低 ρ 且真正「錯題互補」的模型組合更有機會帶來收益
對技術決策者而言,這個 Space 更像一個模型編排可行性檢查工具。它提醒人不要把 orchestration 當成免費性能加成:當共同失敗率高,多模型系統增加的可能只是成本、延遲與系統複雜度,而非可觀準確率提升。