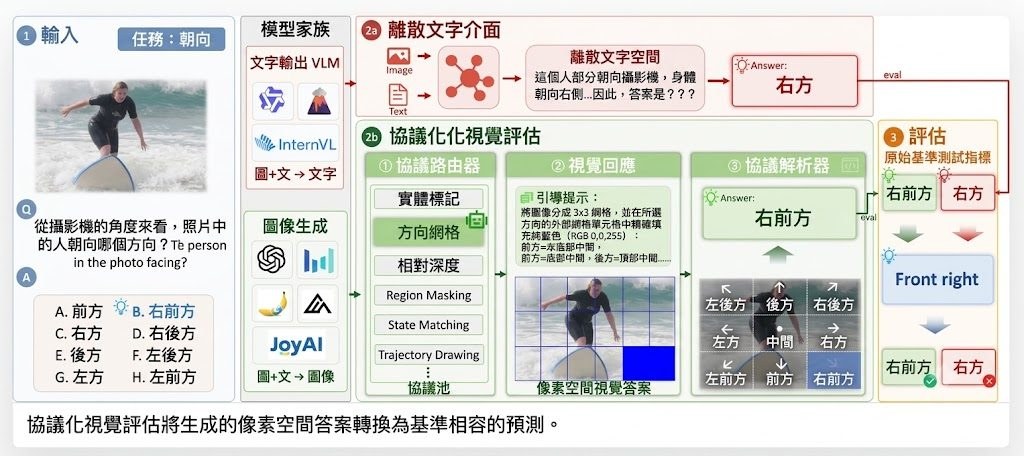
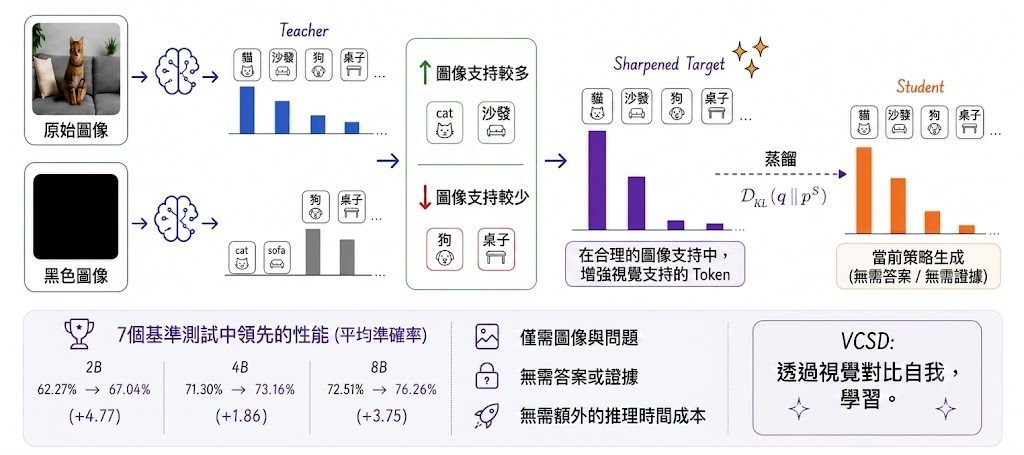
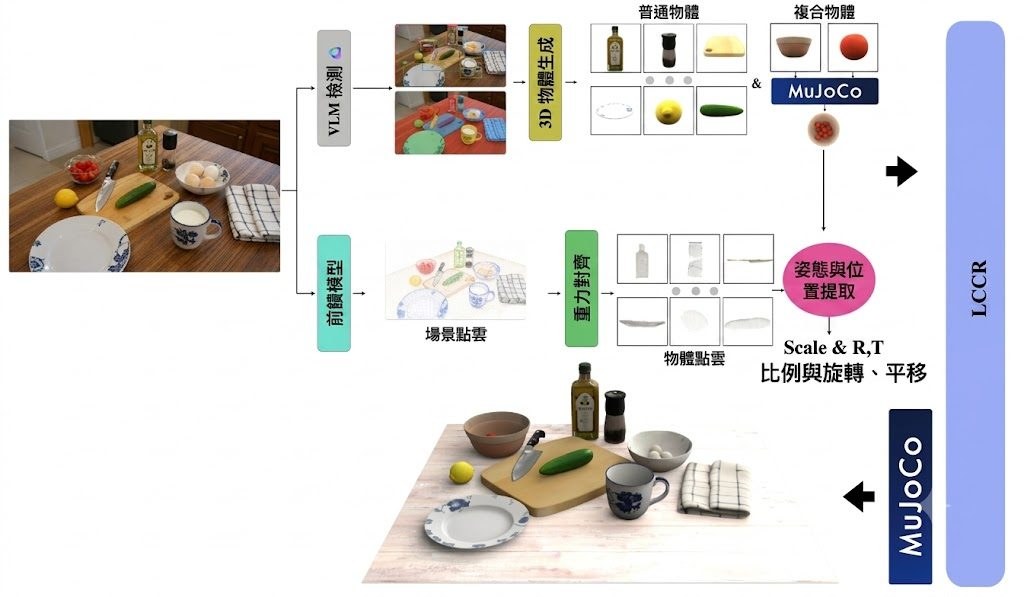
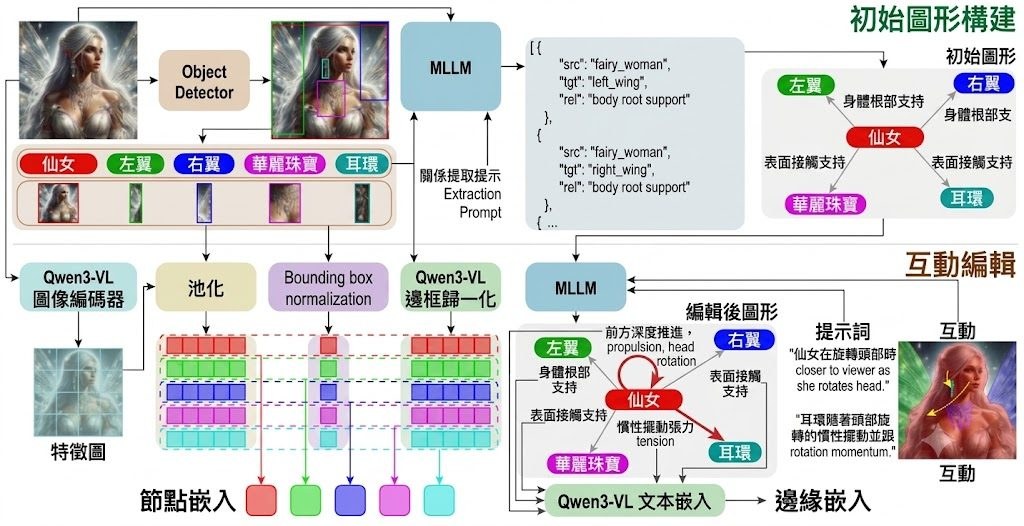
想像你透過手機或頭戴裝置睇現場畫面,明明場景喺眼前,畫面顏色同亮度卻總有一層隔膜。Color Pass-Through 針對的正正係呢種 camera-display 不一致:它屬於影像處理研究項目,以端到端方式學習固定裝置上的 camera-display 路徑,目標唔係單獨校正相機或螢幕,而係令人經過裝置觀看時,感知上更接近真實場景。
作者明確反對傳統 ICC workflow 呢種兩段式校準範式。舊做法會先分開處理相機同顯示器,再靠預先定義的中介色彩空間接駁,誤差容易逐步累積;Color Pass-Through 改為直接學完整投影路徑,並為每位觀察者做 one-step calibration。呢個取向的好處係更貼近人眼最終見到的結果,代價就係它依賴特定 device pair,同時帶有 observer-specific 設定,泛化方式同傳統標準化流程唔一樣。
目前公開資訊顯示,項目已放出完整 training and inference pipeline,並提供兩款支援裝置的 pretrained checkpoints,所以較合理的理解方式係:它首先係研究原型,其次先係可重現的程式碼。資料集仲準備公開,Android toy example 亦仍在開發中,部署重點暫時仍然放喺已支援裝置上重現論文結果,而唔係即插即用地套入任何手機。
- 核心改動係把 camera 與 display coupling,唔再經固定中介色域分開校正
- 以每位使用者一次校準換取更貼近主觀觀感的色彩與亮度表現
- 人類評分提升 +2.0 分(5 分制),亮度 4.32/5,色彩 4.03/5
- 定量結果亦有明顯優勢,PSNR、ΔE、STRESS 在兩款商用手機上都優於列出的基線
同類方法很多時會加強 white balance、ColorChecker mapping,或者在既有 ISP 後面再補一層修正;這個項目則直接把問題重寫成特定裝置、特定觀察者的整體感知重建。對做 AR/VR pass-through、顯示校準、計算攝影研究的人最有參考價值,尤其當重點唔係標準色彩流程有幾完整,而係人眼最後見到的畫面到底似唔似真景。