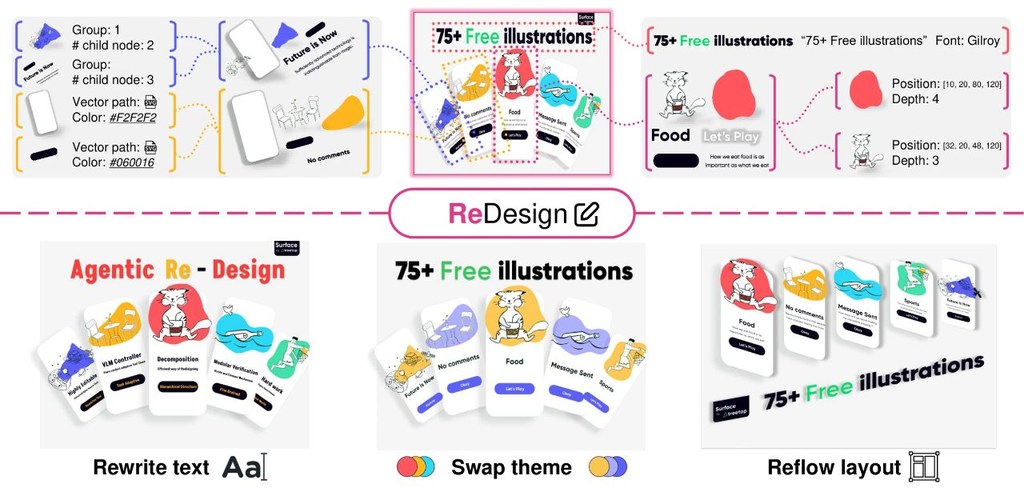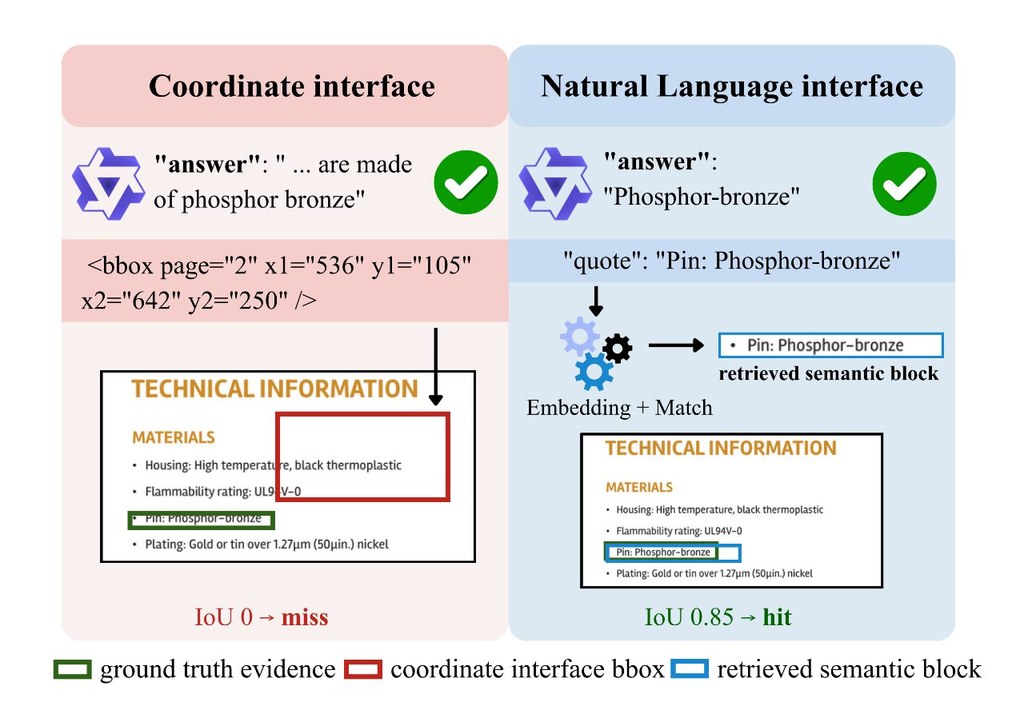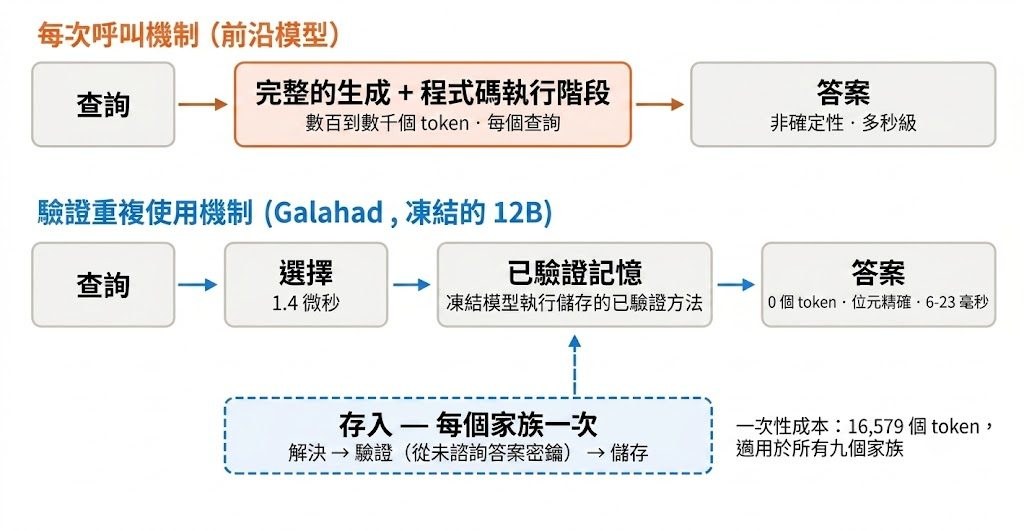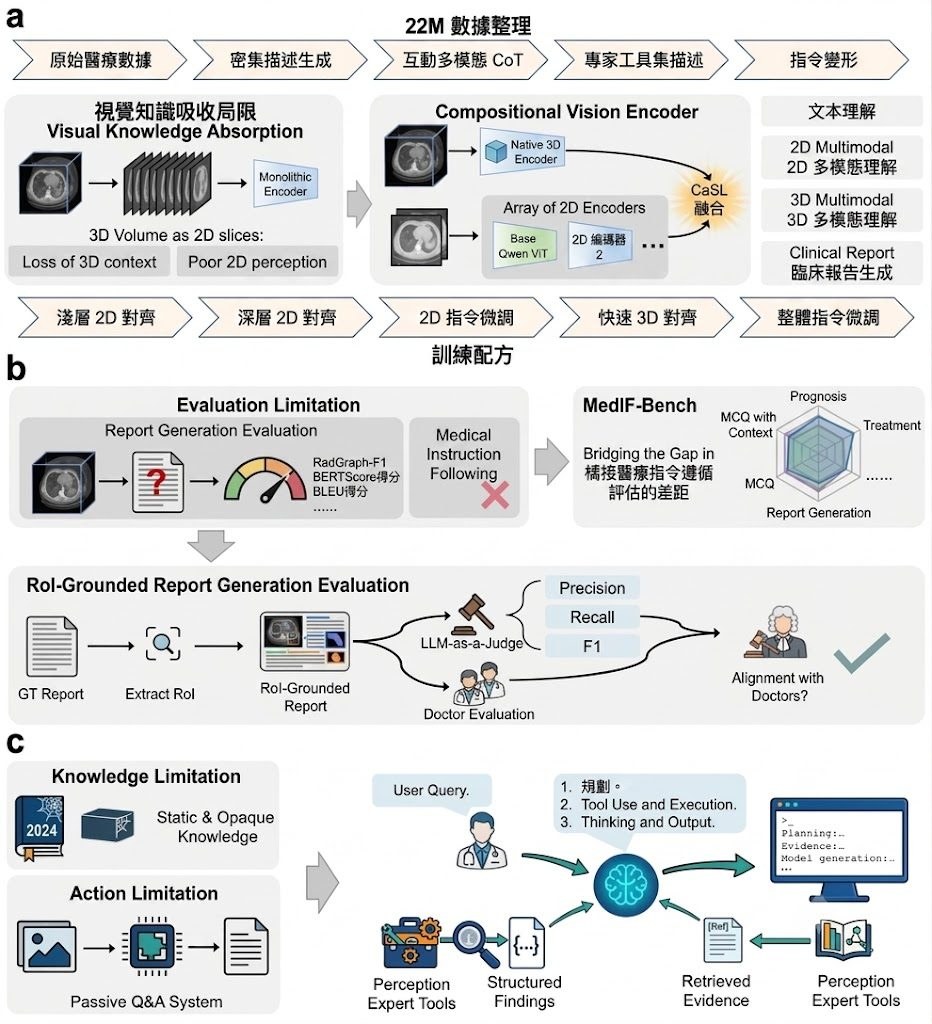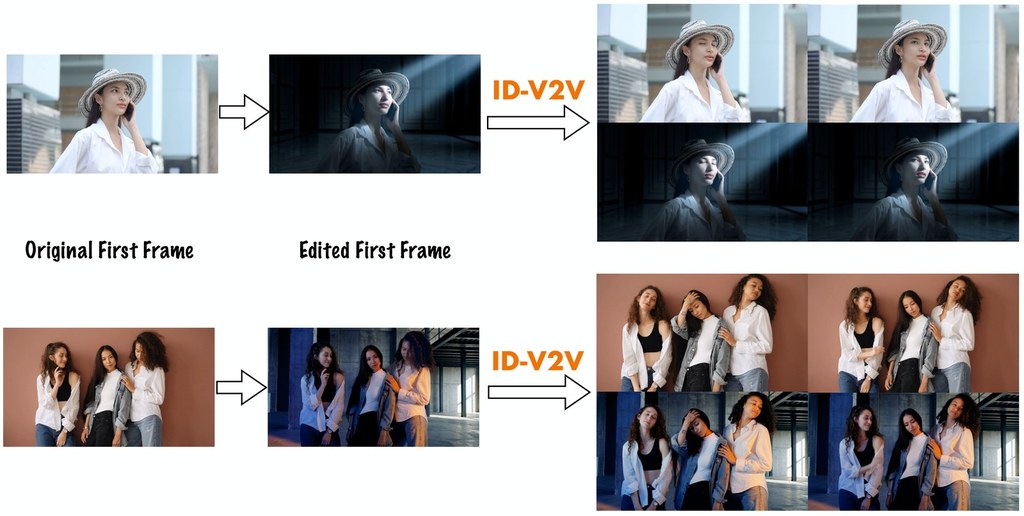
開發團隊來自 Netflix 與 Eyeline Labs。這個研究項目瞄準影像製作中最棘手的一段流程:想改影片風格、場景氣氛甚至補做光線,但又不想犧牲演員的表情、眼神、口型同步和肢體動作;ID-V2V 屬於 video-to-video 生成框架,處理的正是這種「保留身份與表演、再把風格傳播到整段影片」的問題。
現有做法常把影片重繪理解成一般風格轉換或逐格生成,作者認為這種範式很難同時守住 facial likeness 與細微 performance。ID-V2V 的切入點是把 identity preservation 重新表述成 video relighting,再把 edited keyframe 帶來的風格變化交給 controlled video synthesis 處理,並結合 relit facial regions、facial normal maps、edited keyframes 與 depth sequences,將身份約束與整體畫面變化拆開處理。
這個取向的價值很直接:你先拍好 source video,再準備一張 stylized keyframe,系統便嘗試把光線、場景與風格延展到整段片,同時盡量守住人物。原始資料亦提到 imperfect keyframe 的情況,即使首張風格幀和原片姿勢未必完全對齊,模型仍會在之後的幀數重新貼近 source video 的身份與表演,這點比只追求單幀好看更貼近製作流程。
- 提供兩個模型變體:
idv2v以及加入 normal-depth 訊號的版本 - preprocess → generate 的推理流程與輸入輸出結構
- 環境集中在單一
uv環境,另需下載多個 checkpoints,預設資源需求相當高 - 已測試於 8× A100-80GB,代表它較接近研究與製作級部署,不是輕量玩具
- 項目定位寫得很清楚,只供 demonstration and inspiration purposes
部署與測試資訊算完整,提供環境設定、checkpoint 下載、推理流程和多種案例,但門檻不低:需要 Python 3.10、torch 2.6+cu118、SAM3 權限,以及連同 Wan2.1 相關元件在內的大量模型檔案。性能方面,項目與首頁都表示在 preserving facial likeness 與 fine-grained facial performance 上明顯優於既有方法,並支援 single-subject 與 multi-subject 場景。