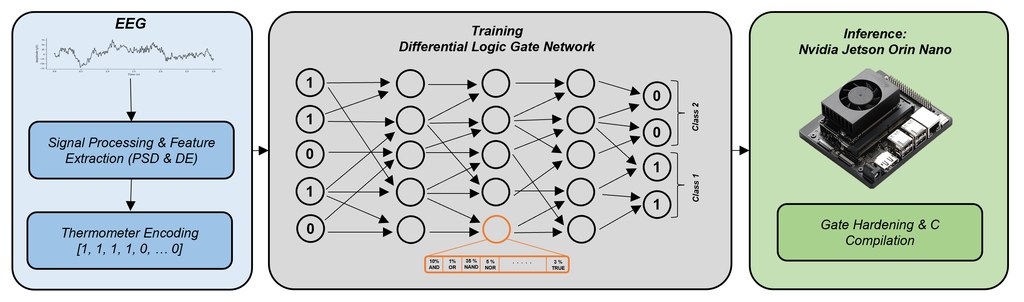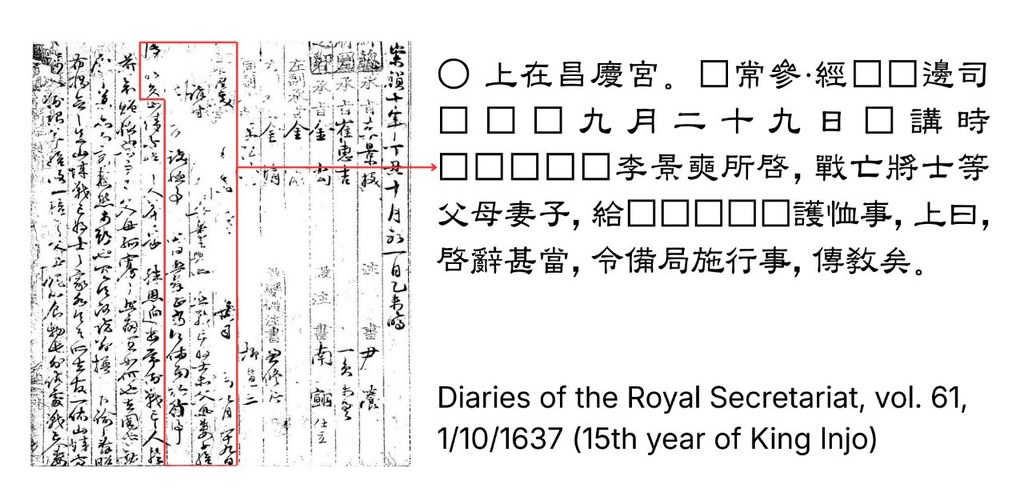
最值得留意的,不是模型把缺字補回來本身,而是它專門處理古籍修復最棘手的一類內容:人名、地名等 Named Entities。ARI 屬於一個結合 Retrieval-Augmented Generation(RAG)的文獻修復框架,針對朝鮮王朝實錄與承政院日記這類韓文漢字史料,補足只靠局部語境時經常失準的缺口。
現有做法多數依賴 masked language modeling,擅長根據前後文猜測一般字詞,但一遇到需要外部史實支持的專名就容易失手。ARI 的取向很清楚:先用 BM25 從歷史語料找出前 20 份相關文本,再以字串相似度 0.8 過濾重複內容,將這些外部證據交給模型一併生成,修正通用 LLM 容易出現的幻覺。
模型部分不是從零開始,而是建基於 Qwen3 32B 與 Qwen3 8B 微調成 ARI-32B 和 ARI-8B,並加入 25% named entity-prioritized masking 訓練策略,把學習重點放在知識密集片段。論文亦指出,對漢字材料而言,詞彙層面的 BM25 檢索比 embedding-based retrieval 更有效,這一點頗有說服力,因為表意文字的字形與字詞對應關係本身就影響檢索效果。
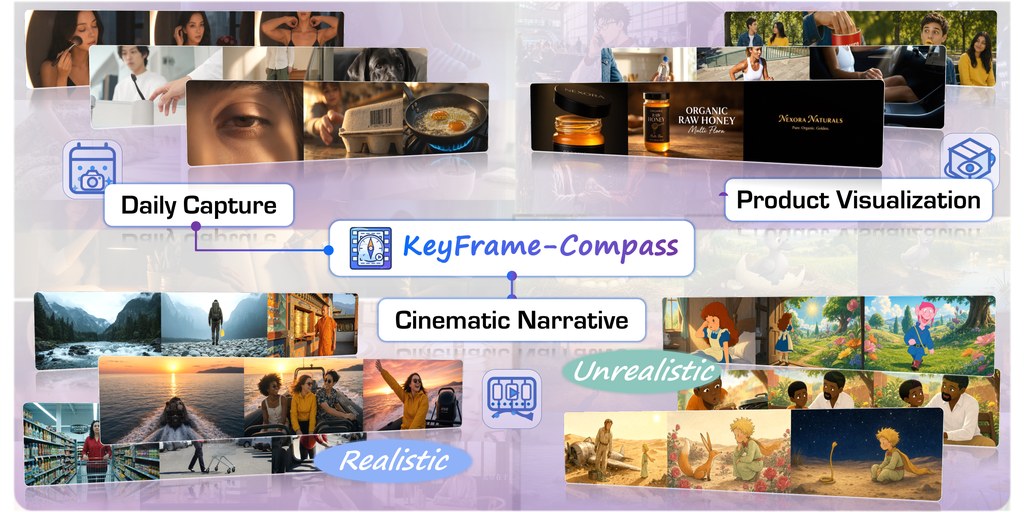
- 適合歷史文獻整理、數位人文研究與古籍校勘團隊參考
- 主要強項在於修復需要外部知識支撐的 Named Entities
- ARI-32B 與 ARI-8B 同步提供,前者追求表現,後者較重視運算成本
- 論文結果顯示,它在 named entity 與隨機遮罩字元修復都勝過多個基線與通用模型
把它視為一個已有公開模型與方法說明的研究項目。對需要先驗證效果的人來說,現階段較合理的路線會是先查看論文設定與模型頁面,再判斷是否足以接入自己的古籍修復工作流。