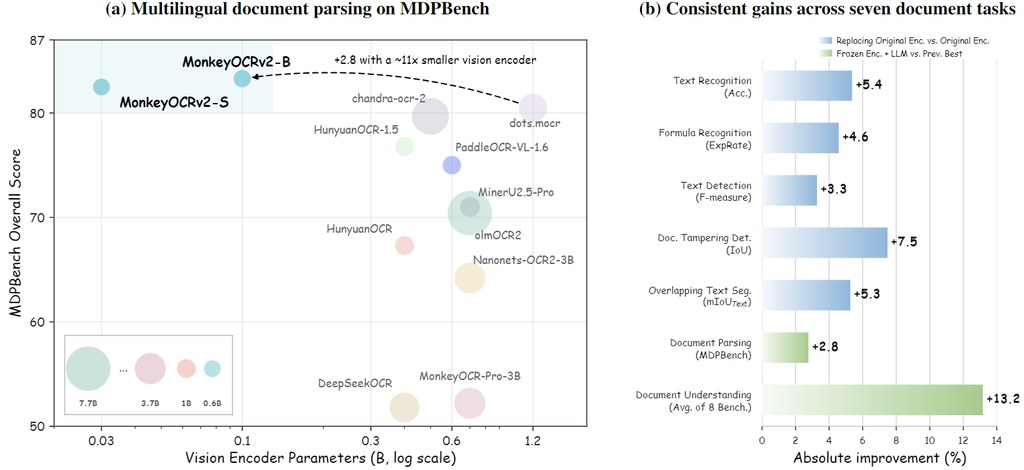
單靠一張圖片生成大角度新視角,很多方法一轉得遠就會出現結構鬆散、比例飄移,鏡頭控制亦未必準。MetaView 屬於影像生成框架,集中處理 monocular novel view synthesis,目標是在不做顯式 3D reconstruction pipeline 的前提下,仍然保住 geometry consistency 同可控的 camera pose rendering。
它的取向幾清楚:唔想被重建流程綁死泛化能力,但又唔接受純 implicit 方法常見的 scale drifting。項目把 Depth Anything 3 提供的 implicit geometry priors 接到 pretrained MM-DiT backbone,做法是加入 non-invasive parallel attention layers;同時再用 modified RoPE,配合 PRoPE 為 z-axis 留出額外子空間,把場景尺度固定在較一致的 3D metric space。
對研究團隊、做 novel view synthesis、3D-aware image generation,或者需要從單張圖控制鏡頭輸出的工作流,這個項目值得留意。現有資訊較像研究原型:README 與 project homepage 已提供 paper、demo 與 model 入口,但未見完整安裝與部署細節,所以現階段較合理的理解方式,是先用 demo 看大視角轉換與 spherical poses control 的效果,再等待公開模型與程式流程補齊。
- 單張圖片輸入,主打大幅度 viewpoint changes 下仍保持高保真輸出
- 不走 explicit 3D reconstruction pipelines,換取更高彈性與泛化空間
- 用 Depth Anything 3 幾何先驗補結構,再用 modified RoPE 處理 scale anchoring
- 比較對象包括 ViewCrafter、Gen3C、Voyager、PE-Field、HY-World、Lingbot-World
MetaView 在具挑戰性的 monocular large viewpoint changes 測試中,表現優於多個 reconstruction-based 與 implicit 方法,強調的是 geometry consistency、precise controllability 與 generalization。現階段較適合把它視為一個方向鮮明的研究項目:它不是單純追求更靚畫面,而是嘗試把單圖生成長期欠缺的空間尺度感補回來。