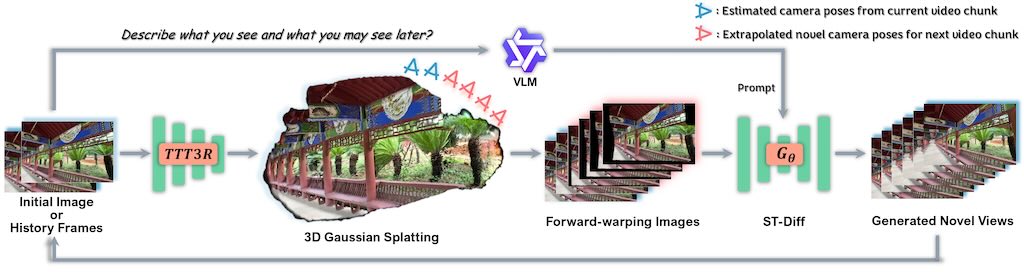
ProEdit 透過 KV-mix 在注意力層融合源/目標特徵,及 Latents-Shift 擾動潛在空間,實現高保真編輯。 支援 FLUX、HunyuanVideo 等模型,同時亦整合 Qwen3-8B 解析自然語言指令。
ProEdit 解決傳統反轉編輯過度依賴源圖的問題,能準確變換主體屬性如姿態、數量、顏色,同時保持背景一致。 適用於圖像替換(如老虎變貓、襯衫變毛衣)與影片動態編輯(如紅車變黑車、鹿變牛)。適合 AI 內容創作者、影片後製,plug-and-play 相容 RF-Solver 等工具,在多項基準測試達 SOTA 效能。
ProEdit: Inversion-based Editing From Prompts Done Right