CoF-T2I 模型透過漸進式視覺細化,將 CoF 推理整合到 T2I 生成過程中,其中中間幀作為顯式推理步驟,最終幀作為輸出。為了建立這種明確生成過程,CoF-T2I 建立了CoF-Evol-Instruct 資料集,該資料集包含從語義到美學的 CoF 軌跡,用於建模生成過程。為了進一步提高品質並避免運動偽影,CoF-T2I 對每一幀都進行了獨立編碼。實驗表明,CoF-T2I 的性能顯著優於基礎視訊模型,並達到了具有競爭力的水平。
影片主要在介紹幾個最新的生成影音工具與功能,包括 PixVerse R1 即時「世界模型」視頻、Flux 2 Klein 圖像模型、Runway 的 Story Panels、Google Veo 3.1 更新,以及開源的 Wonder Zoom 專案。

3AM 是一種結合了 2D 即時分割模型 SAM2 與 3D 幾何資訊的方法,目的是在影片或任意多視角圖像集合中,對同一物體保持一致的分割 mask。傳統的 2D 追蹤模型(如 SAM2)在觀點大幅變化時會因為只能依賴外觀特徵而失去目標,而早期的 3D 方法則需要提供相機位姿、深度圖或複雜的前處理,才能保證跨視角的一致性。
3AM 的創新在於在模型訓練階段,透過輕量的特徵合併模組把從 MUSt3R(一個多視角重建模型)學到的隱式幾何特徵與 SAM2 的外觀特徵結合,形成既能捕捉空間位置又能反映視覺相似度的表示。這樣的融合讓模型在推論時只需要原始 RGB 影像和使用者提供的提示(點、框、mask 等),就能在不同觀點之間追蹤物體,且不需要額外的相機資訊或前處理步驟。文章指出,這種做法在包含大量視角變化的基準測試集(如 ScanNet++、Replica)上,IoU 數值提升顯著,例如在 ScanNet++ 的 Selected Subset 上比 SAM2Long 高出約 15.9 個百分點。整體而言,3AM 在保持即時、可提示化的特性同時提升了跨視角的一致性,為後續的 3D 實例分割與多視角物體追蹤提供了一個更簡單、更有效的解方案。

VINO 是個統一的視覺生成工具,能同時處理圖像和影片的創作與編輯,無需針對每種任務去找不同的模型。它的核心架構是把視覺語言模型和多模態擴散轉換器(MMDiT)結合起來,讓文字、參考圖片或影片都能以同一套條件流動的方式被傳遞給擴散過程。
這裡的「可學習查詢 token」扮演的角色是把使用者的簡短指令轉化成模型能理解的細節向量,並在訓練時一起調整,讓指令更精確、模型更穩定。另一個關鍵在於把參考影像或影片所產生的特徵與它在 latent 空間的對應向量用同樣的開始與結束標記包起來,這樣模型就能在語意層面和潛在層面都把同一個參考資源針對地辨識出來,減少身份混淆或屬性遺漏的問題。
InfiniDepth 把傳統的深度圖想成一個可以在任何二維座標上即時查詢的隱式場(Implicit Field),而不是固定在像素格子裡。這樣的表示方式讓模型不再受到訓練解析度的限制,能夠直接輸出任意高解析度的深度圖,同時保留更細緻的幾何細節。
NeoVerse 是一種強大的 4D 世界模型,專門設計來處理現實環境中的單眼視頻,從而實現多種應用。這個模型的核心優勢在於它能夠進行無姿態限制的前饋 4D 重建,這意味著它可以從普通的單眼視頻中直接生成高質量的 4D 場景,而不需要複雜的多視角數據或預處理步驟。
PlenopticDreamer 主要解決「鏡頭控制生成影片」的不一致問題。這是一個能讓 AI「像無人機一樣繞著物體飛」生成影片的技術。它可以應用在自駕車的模擬環境、機器人的視覺訓練,以及好萊塢等級的虛擬拍攝。
1. Robotics(機器人):
* 情境模擬: 機器人需要理解物體在不同角度下的樣貌。這個技術可以根據單一攝影機的畫面,生成該物體在其他視角的影像,幫助機器人進行視覺導航或物體抓取的訓練。
* 模擬數據生成: 為機器視覺系統生成更多樣化的訓練數據。
2. Self-Driving(自駕車):
* 場景理解: 自駕車通常有多個鏡頭。這個技術可以補足盲區,或者將一個鏡頭的畫面轉換成其他鏡頭的視角,幫助車輛更全面地感知周圍環境。
* 未來幀預測: 預測道路上物體在下一秒鐘會出現在哪個位置(從不同角度)。
3. 影視製作與 AR/VR:
* 新視角補全: 如果拍攝時漏掉了某個角度,可以利用這個技術「憑空生成」該角度的連續影片。
* 重定向(Re-direction): 可以將拍好的影片,根據新的鏡頭軌跡重新渲染(Re-rendering),讓同一段故事可以從不同角度重新看一遍。
VerseCrafter 是一套以 4D 幾何控制驅動的影片擴散模型,目標在單張參考圖上同時掌控相機運動與多目標的三維軌跡,讓生成的影片在視角變化與物體遷移間保持高度一致。讓使用者能夠像操控遊戲或電影一樣,精確控制鏡頭和物體的運動,從而生成逼真的動態影片。
一般的 AI 影片模型通常難以同時掌控鏡頭移動和多個物體的動作,VerseCrafter 透過一種全新的表示法解決這個問題:1. 動態世界模擬:它不只是畫出一連串的畫面,而是先在一個隱藏的 3D 空間中建立場景的基礎結構(例如背景點雲),然後加上時間軸,變成 4D。2. 精準控制:鏡頭:你可以指定鏡頭要怎麼飛行(例如從左邊飛到右邊,或是繞著物體旋轉)。你甚至可以指定畫面中的物體要如何移動、旋轉。
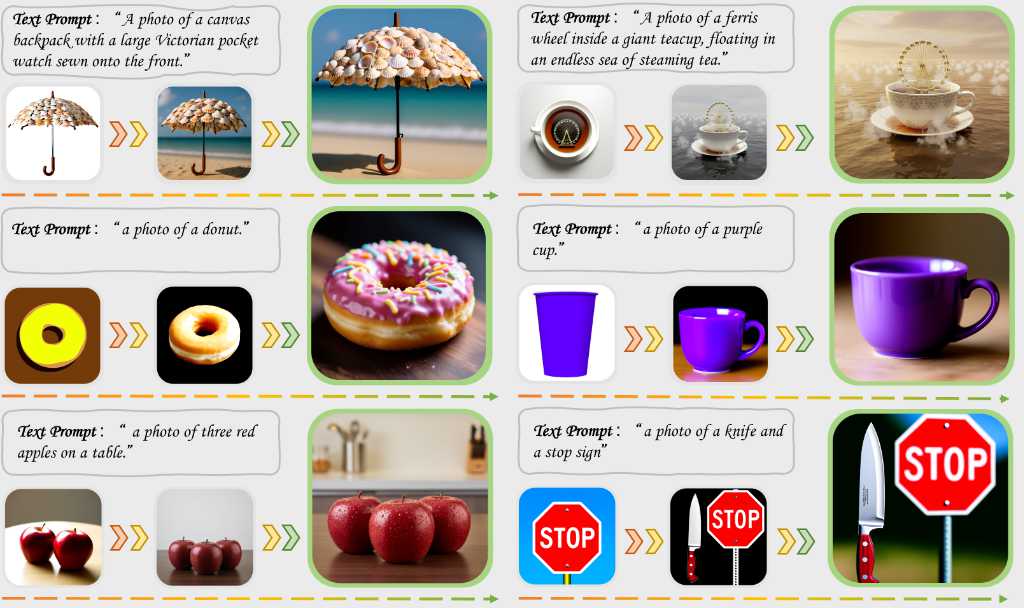
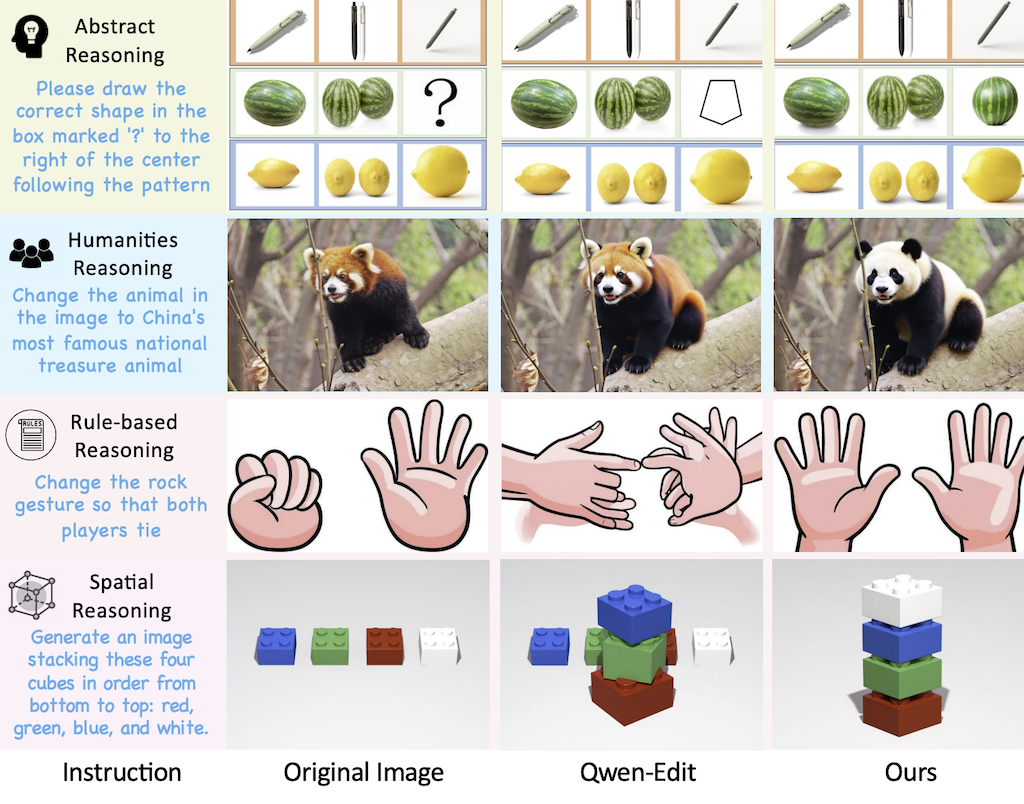
由 ByteDance (字節跳動)提出 ThinkRL‑Edit: Thinking in Reinforcement Learning for Reasoning‑Centric Image Editing「推理導向」圖像編輯,指現有的 RL‑based 編輯方案受限於三個問題:探索空間只在去噪隨機性、獎勵函數的加權不夠公平、以及 VLM 判斷獎勵可能不穩定。作者提出的 ThinkRL‑Edit 框架將視覺推理與影像合成分開,並利用 Chain‑of‑Thought 產生多層次的推理樣本,包含策劃與自省兩個階段,讓模型在實際產生圖像前先評估多種語意假設的可行性。這樣的設計讓探索不再受到去噪過程的束縛,並透過無偏的獎勵策略提升圖像編輯的精確度與一致性。
Gen3R 是一個將基礎重建模型與視訊擴散模型結合的框架,目標是從單張或多張圖片生成包含 RGB 影片與幾何資訊的 3D 場景。如果你對於用影片資訊直接生成 3D 幾何感興趣,這是目前最接近「一鍵產出完整場景」的方案之一。
核心流程是:先把 VGGT 重建模型的 token 包成幾個幾何潛在變數,再用一個 adapter 把這些潛在值推向影片擴散模型的外觀潛在;兩種潛在同時生成,互相對齊後就能一次產出 RGB 影片 plus 完整的 3D 幾何資訊(相機姿態、深度圖、全局點雲)。
實驗顯示在單張或多張圖像條件下都能得到最佳的 3D 場景生成結果,而且透過擴散先驗提升了重建的穩定性。整體上是把重建跟生成模型「緊密」捆綁在一起,而不是分開處理。
