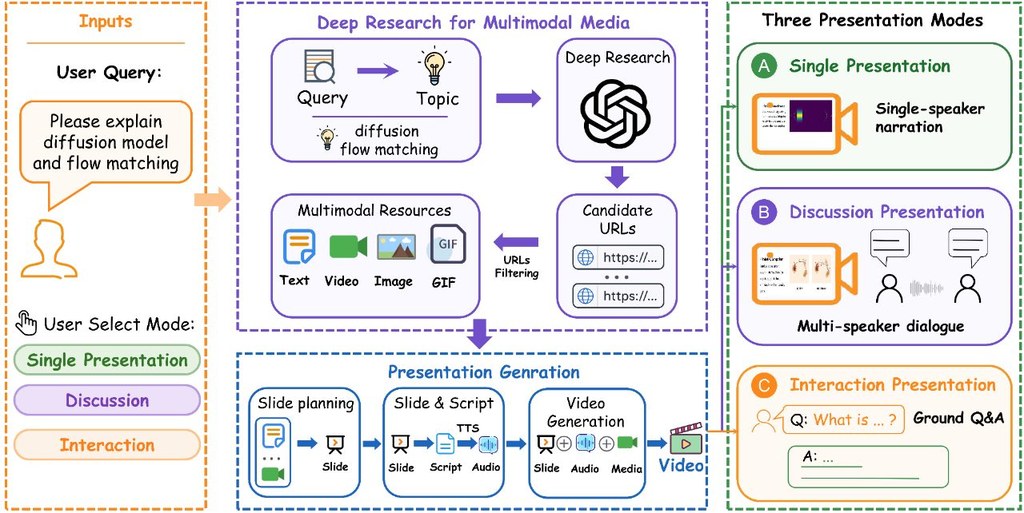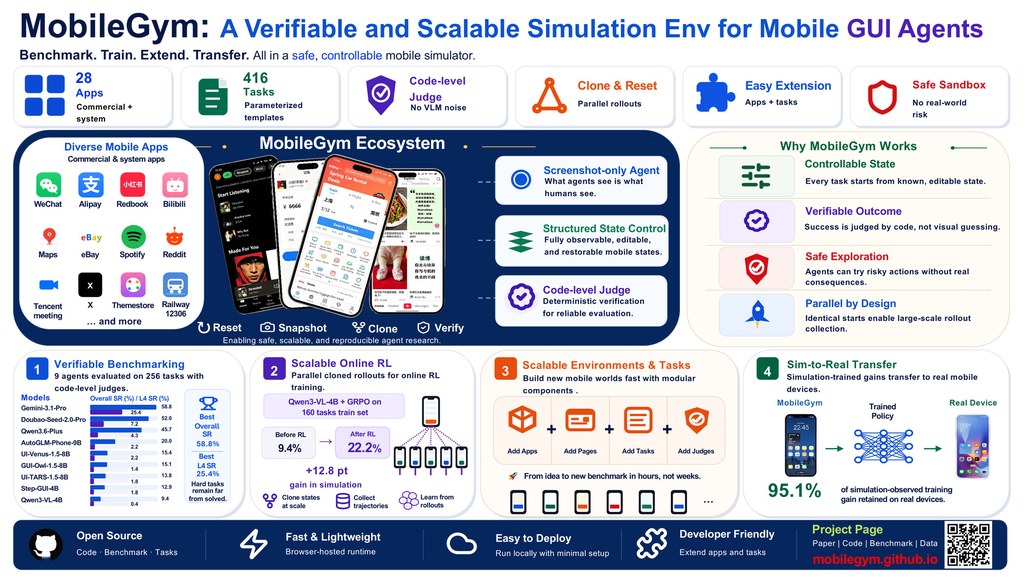
MobileGym 是一個放在瀏覽器內運行的手機模擬環境,重點不是做出一部「像真手機」,而是讓研究者可以穩定測試手機操作代理。它針對真機與模擬器常見的難題,例如狀態難以重現、評分不穩、成本高,提供一套較可控的做法。
使用相當直接:先開啟模擬環境,再把代理接上去執行任務,之後用內建評分函式檢查有沒有完成目標。這個項目提供 28 個模擬 app、416 個任務模板,也支援把整個環境狀態存成 JSON,方便重設、比較與重跑同一組測試。
MobileGym 在「結果驗證」不靠模糊文字比對,也不依賴視覺模型做人手味很重的判斷,而是直接檢查結構化狀態。這代表系統不止能知道任務是否成功,還能發現副作用,例如錯誤追蹤了某個帳戶,或誤發訊息,這類情況在真機流程往往較難完整看見。
- 支援 256 個並行實例,同一台伺服器可同時跑大量測試
- 每個實例約 400 MB 記憶體,冷啟動約 3 秒
- 評分為可程式化且具決定性,官方稱可達亞毫秒級
- 已展示模擬到真機的轉移效果,保留約 95.1% 的訓練增益
性能數字是這個項目的另一個賣點:官方資料指 256 個任務的完整評估可在約 6 分鐘完成,而且 CPU 佔用不高。對需要反覆訓練、比較不同策略或模型的人,例如 Qwen3-VL-4B 搭配 GRPO 這類流程,這種可並行、可重現的設計比單靠真機測試更實際。
整體來看,MobileGym 適合做手機 GUI 代理研究、評測流程設計,以及強化學習訓練驗證。它未必取代真機,但作為前期迭代與大規模評估平台,定位十分明確;尤其當你重視可重現性、成本控制,以及能否清楚知道代理到底做對了甚麼、又做錯了甚麼,這個項目值得留意。