一邊輸入文字、一邊指定角色要去邊、幾時抬手或者身體要擺成咩姿勢,系統仍然可以即時生成自然動作;ARDY瞄準的正正是呢種互動式 3D human motion generation 場景。呢類能力對動畫、模擬同 humanoid robotics 都重要,因為傳統離線方法雖然控制精準,但速度未必跟得上互動需求;純即時方法又常常在語意理解、長距離目標同約束服從度上打折扣。
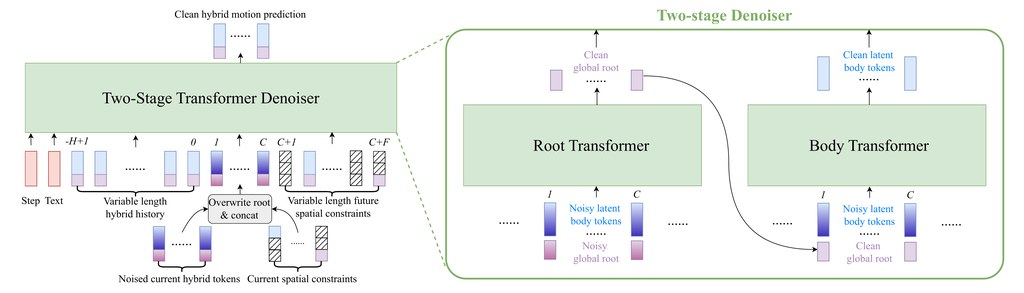
ARDY 採用 autoregressive diffusion model,同時配合 hybrid representation,把角色移動軌跡相關的 root features 同 latent body embedding 結合。咁樣做的用意很直接:一方面保留對路徑與朝向的明確控制,另一方面維持生成模型學習複雜全身動作時的效率與彈性。配合 two-stage autoregressive transformer denoiser,同一套框架可以處理 online text prompting,亦能接住較長時間範圍的 kinematic constraints。
它支援的約束方式幾完整,包括 root paths、waypoints、full-body keyframes,以及 sparse joint positions/rotations,亦可混合使用。更重要的是,約束唔一定只限當前生成視窗,較遠將來的目標都可以先講定,令角色更容易朝長程目標連續行動,而唔係每幾步就失去方向。
- 支援 online text-to-motion generation,可即時改提示詞
- 可加入 root paths、waypoints、full-body keyframes 同 sparse joint constraints
- 兼顧即時反應、動作品質同長距離控制
- 面向動畫、模擬、humanoid robotics 等互動工作流
資料提到,ARDY 以大型 motion capture dataset 訓練,並直接用文字標籤與來自真實姿勢抽樣的 kinematic constraints 作條件,令模型原生學會受控生成。研究團隊亦展示了互動式 demo,涵蓋動態文字控制、關鍵幀約束、路徑跟隨同即時 locomotion control;定位上,它較適合需要邊調邊看結果的內容製作與研究場景。
![[ECCV26] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation & Spatial Intelligence](https://infernews.com/blog/wp-content/plugins/wp-youtube-lyte/lyteCache.php?origThumbUrl=https%3A%2F%2Fi.ytimg.com%2Fvi%2FoZiwNBSqRZU%2F0.jpg)