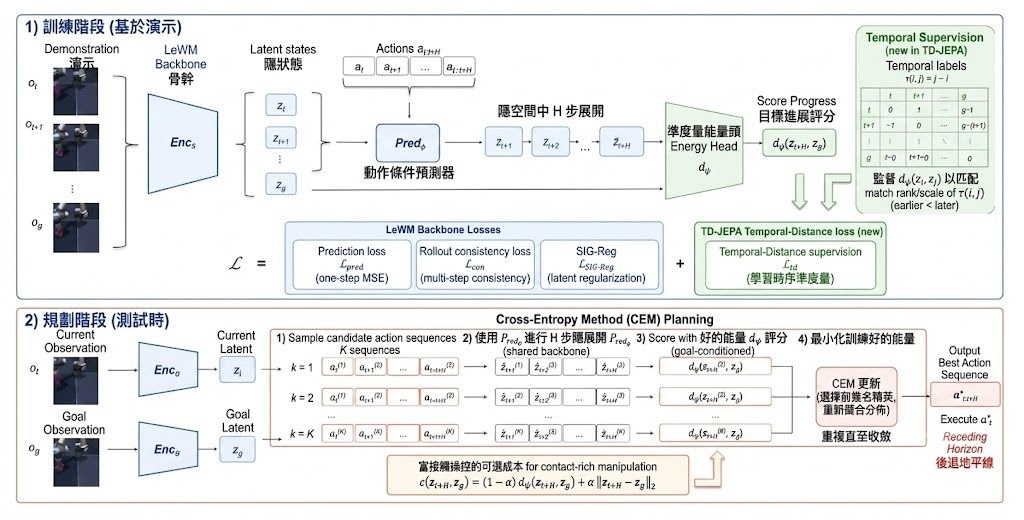
生成影片最難處理的,往往唔係畫面清唔清,而係物件點移動、碰撞同延續。PhiZero 屬於世界模型(World Model),焦點放在「先理解世界狀態點轉變,再生成畫面」,用較細緻的 physical language 去表達變化,減少直接由像素預測帶來的不穩定感。
它想解決的問題很明確:自然語言太粗略,難以完整描述複雜物理過程;純視覺生成又未必能穩定保留因果同動作連貫性。PhiZero 於是從大量無標註影片學出一套 compact discrete representation,先把相鄰影片狀態之間的轉變編碼成 physical language,再交由模型根據首幀畫面同文字動作意圖,預測之後的狀態序列,最後渲染成影片。
它採用 reason-then-render 流程。前段由 Physical Language Tokenizer 抽取相鄰 latent video states 的有序特徵,配合 FSQ 離散化成 physical language;後段由以 Qwen3-VL-4B 初始化的 autoregressive VLM 負責推演,再用訓練好的 diffusion decoder 輸出影片。這種拆法的價值,在於同一套 transition representation 可以重用在 physically realistic generation、action-conditioned simulation、interactive rollouts 同 zero-shot transfer,而唔係只限單一生成任務。
- 先推演世界轉變,再生成影片,重點放在因果與動作連續性
- physical language 來自無標註 in-the-wild videos,自監督學習轉變結構
- 以 Qwen3-VL-4B 作為 reasoner 基礎,並擴充 25K atomic symbols 詞彙
- 同一表示方式可支援生成、模擬、互動 rollout 同 transfer
現有資料顯示,PhiZero 的訓練資料同時結合真實與模擬影片,並經過逐步篩選,令模型由廣泛視覺經驗收斂到較多動態互動片段。官方頁面已展示 demos,但程式碼仍標示為即將推出,所以現階段較適合把它看成一個值得關注的世界模型方向:它不是單靠更大影片模型硬推結果,而是嘗試先建立可推理、可重用的物理語言介面。