Skill0.5 是一個面向 Agentic Reinforcement Learning 的研究項目,聚焦處理 out-of-distribution generalization 問題。它指出傳統 skill-based RL 方法常要在 full externalization 與 full internalization 之間二選一,前者會帶來高昂的 context 開銷,後者則容易出現 overfitting 與知識衝突。
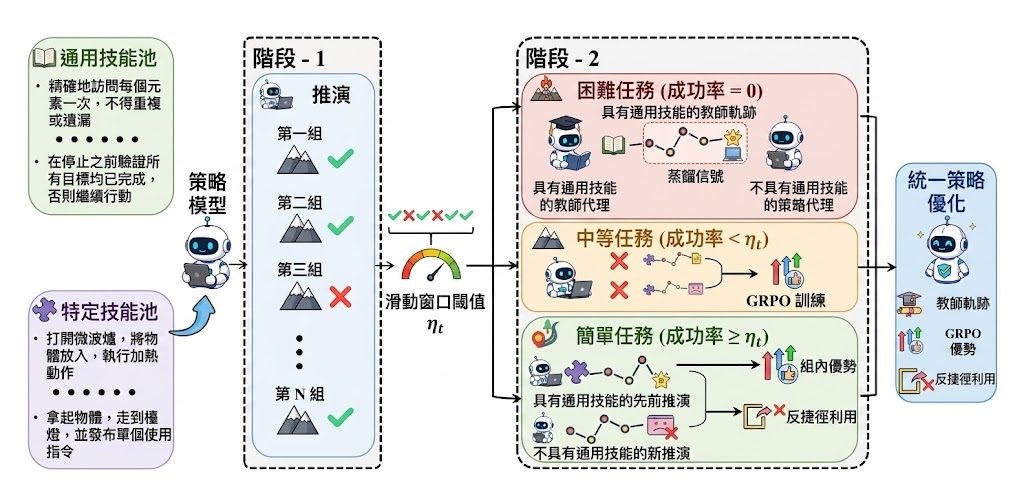
這項目把 general skill internalization 與 task-specific skill utilization 一同納入訓練,但用不同策略處理兩種性質不同的技能。系統會用 difficulty-aware router 按任務難度分流:Hard tasks 用 privileged distillation 內化通用技能,Medium tasks 用標準 RL 提升成功率,Easy tasks 則透過 diagnostic probing 懲罰走捷徑的行為,迫使模型忠實運用任務相關技能。
對初步理解這個項目的人來說,可先把它視為一種「按難度分工」的訓練框架,而不是單一模型結構。使用時要留意 context 開銷被視為問題之一,某程度上也反映較重的外部技能依賴可能增加資源壓力,包括 VRAM 與序列處理成本。
- 解決 rigid choice 問題,避免只靠 externalization 或 internalization
- 用 difficulty-aware router 把任務分成 Hard、Medium、Easy 三層
- 分別結合 privileged distillation、標準 RL 與 diagnostic probing
- 在 ALFWorld 與 WebShop 中,據摘要所述優於 memory-based 與 skill-based RL baselines
這類項目較適合研究智能代理、任務規劃與泛化能力的人參考,尤其是想改善模型在陌生情境下穩定性的團隊。
訓練和實現時使用 Qwen2.5-7B-Instruct 作為基礎模型。策略最佳化方面採用 GRPO 作為骨幹網絡,組別大小 G = 8,學習率為 1 × 10⁻⁶。訓練在 4 個 H800 GPU 上進行,每次迭代的批次大小為 16 個任務,最大互動範圍設定為 30 步。任務特定技能透過 Qwen3-Embedding-0.6B 取得。