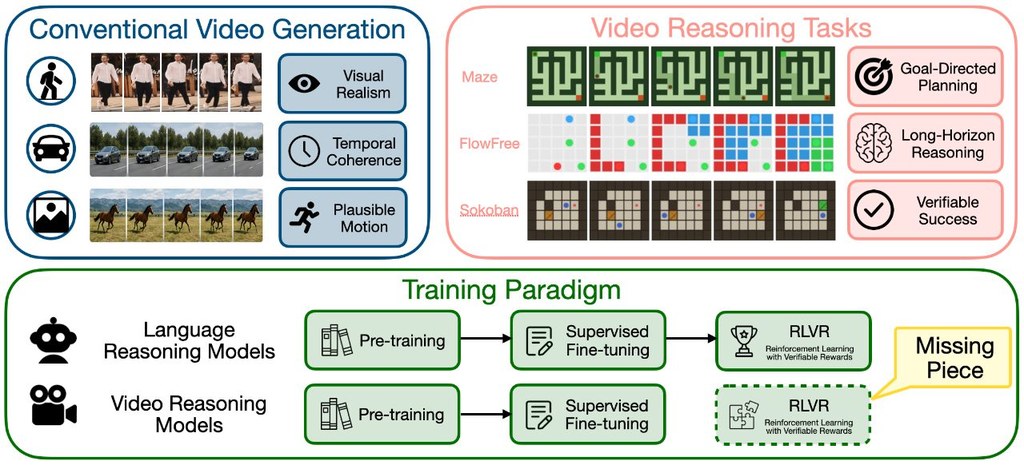
VideoRLVR 是一個用來訓練影片推理模型的項目,核心做法是把強化學習加入影片生成流程,並用「可驗證」的獎勵來判斷答案是否正確。簡單說,它不是只追求畫面像真,而是希望模型在生成影片時,連帶表現出可檢查的解題能力。
這個項目目前圍繞 Wan2.2-TI2V-5B 展開,並以 Maze、FlowFree、Sokoban 這類有明確規則的任務作為訓練與評估場景。這類設計的好處,是模型表現不只靠主觀觀感,而是可以透過任務成功與否來量度,對研究推理能力特別重要。
要理解這個項目,可先由它提供的資源入手:公開集合內有 SFT 與 RLVR 檢查點,也有訓練及測試資料。程式結構亦分開了訓練、推論與評估腳本,並提供多任務及單一任務版本,方便比較不同設定下的結果。
- 重點放在可驗證獎勵,比只看主觀生成質素更易評估
- 以 Wan2.2-TI2V-5B 為基礎,提供 SFT 與 RLVR 相關模型
- 任務涵蓋 Maze、FlowFree、Sokoban,偏向規則清晰的推理測試
- 已整理模型與資料集到 Hugging Face,查找資源較方便
這個項目的新意,在於把影片生成與可量化的推理訓練更緊密地結合,並且明確提供一套可重複的訓練配方。從 README 可見,它亦包含多任務訓練、純成功訊號版本,以及 OOD 推論與評估腳本,表示作者不只關心是否學會指定題目,也在意模型離開熟悉分佈後的表現。
適合留意這個項目的人,包括研究多模態模型、影片生成、強化學習,或想觀察模型如何在規則環境中表現推理能力的開發者。至於性能數字,這份儲存庫摘要未展示完整量化結果,因此較穩妥的看法是:它的價值目前更偏向研究方法、訓練流程與公開資源,而不是單靠一兩個分數定勝負。