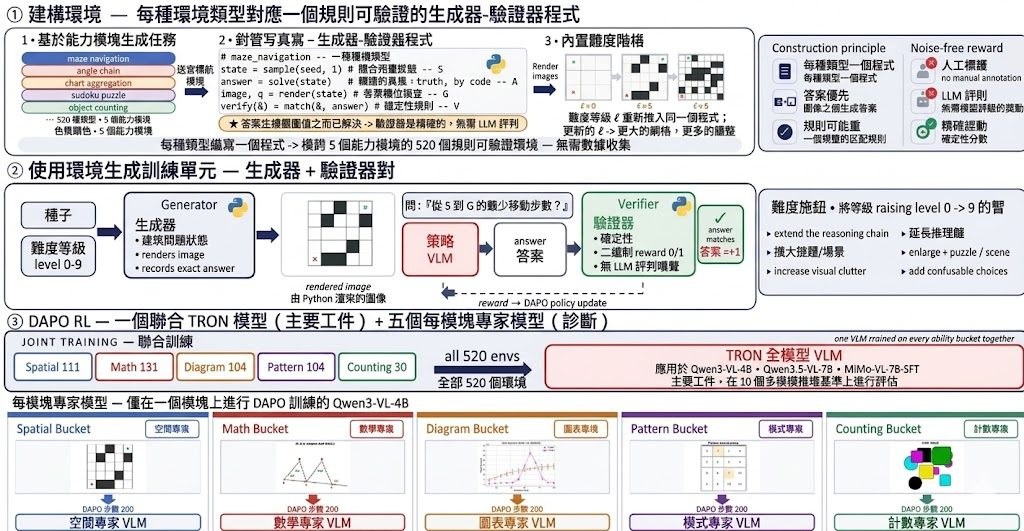
TRON(Targeted Rule-verifiable Online Environments for Visual Reasoning RL)由喬治亞大學運算學院的研究團隊開源,是一個用於視覺推理強化學習的環境套件。與傳統固定的圖文題庫不同,TRON 的每個環境都由「生成器」與「驗證器」組成:生成器負責抽樣新的視覺狀態並繪製圖片,驗證器則即時比對模型答案與標準答案,因此每次呼叫都會產生全新題目,數量上不受既有資料集限制。
這個項目解決的核心問題是視覺推理強化學習長期缺乏可擴展、可控制、可驗證的訓練信號。過往做法依賴人工標註或合成指令的靜態資料集,題目數量受限,且難以針對特定難度與技能做調整。TRON 把每道題目變成可程式化的環境,訓練時可依據當前課程難度持續產出新實例,並由驗證器提供精確的獎勵。
套件規模方面,TRON 包含520個環境,分為五大能力類別:空間(111個)、數學(131個)、圖表(144個)、規律(104個)和計數(30個)。同一套環境可同時訓練一個全能力的「full TRON model」,或分別訓練五個針對單一能力的 specialist 模型。團隊亦針對生成穩定性、題目多樣性、跨環境重複率與基礎模型在不同難度的通過率進行了完整的子環境分析。
訓練與評估部分,項目採用 TRON-DAPO 強化學習方法。使用 TRON 進行 RL 後訓練,Qwen3-VL-4B、Qwen2.5-VL-7B 與 MiMo-VL-7B 等多個多模態模型,在十個外部視覺推理基準測試上都有穩定提升。對想研究視覺 RL 的研究人員或團隊而言,TRON 提供了一個現成、可擴展且易於自訂難度的訓練場景。
重點摘要:
- 520個可程式化的視覺推理環境,分屬空間、數學、圖表、規律、計數五大類別。
- 每次訓練都會即時生成新題目,並由驗證器自動核對答案。
- 支援訓練單一全能力模型或多個單一能力的 specialist 模型。
- 內建子環境分析,涵蓋生成穩定性、難度梯度與基礎模型表現。
- 在多個主流多模態模型上,採用 TRON-DAPO 訓練皆能提升外部基準表現。