SoCRATES 是一個用來評估 Large Language Models(LLMs)在社會衝突中擔任主動調解者的 benchmark。它關注的不是單次答題表現,而是調解過程:兩方在對話中情緒、意圖與情境會不斷改變,模型需要判斷何時介入,以及應該說甚麼,並且不能偏幫任何一方。
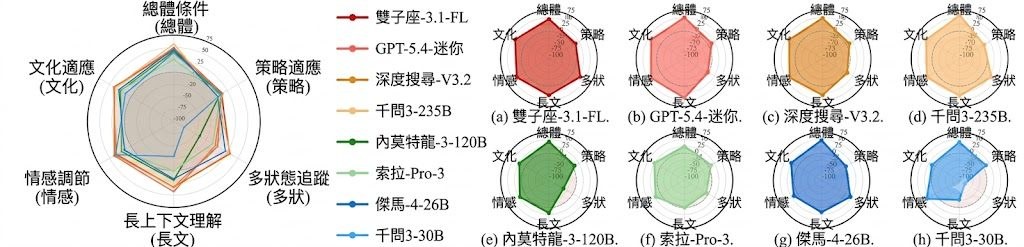
現有測試環境太單一,很多只涵蓋少量由專家撰寫的場景,或者把每一句對話都拿去對照所有議題評分,令結果混入不相關訊號。SoCRATES 則以 agentic pipeline 把真實公開爭議整理成場景,覆蓋八個衝突領域,並沿五條 socio-cognitive axes 測試模型在不同條件下的調整能力。
評分部分採用 topic-localized evaluator,只會在真正推進某個議題的回合上計分,並以三個 metrics 量度調解貢獻,減少離題內容影響結果。
- 以真實公開衝突建立場景,不限單一領域
- 測試 strategic posture、party composition、history length、emotional reactivity、cultural identity 五種變化
- topic-localized evaluator 與人類專家的一致度達 0.82
- 測試八個 frontier LLMs,最強模型亦只填補約三分一未調解時的共識落差
從目前結果看,SoCRATES 適合研究 LLM 調解能力、社會互動能力與多情境適應性的團隊使用,也適合用來比較不同模型在複雜對話任務中的穩定性。數據顯示,表現會因 socio-cognitive axis 明顯波動,說明這類項目的關鍵不只是語言生成,而是能否隨不同人、不同情緒與不同背景作出合適調整。