現有的語言模型自博弈(self-play)訓練方法,大多只能處理有明確對錯的題目,例如數學運算。蘇格蘭愛丁堡大學等機構的研究團隊提出了一個名為 SCOPE(Self-Play via Co-Evolving Policies)的框架,把自博弈拓展到沒有標準答案的開放式任務,例如需要整合多段資料才能完成的問答。研究團隊來自 University of Edinburgh、Imperial College London 與 Miniml.AI。
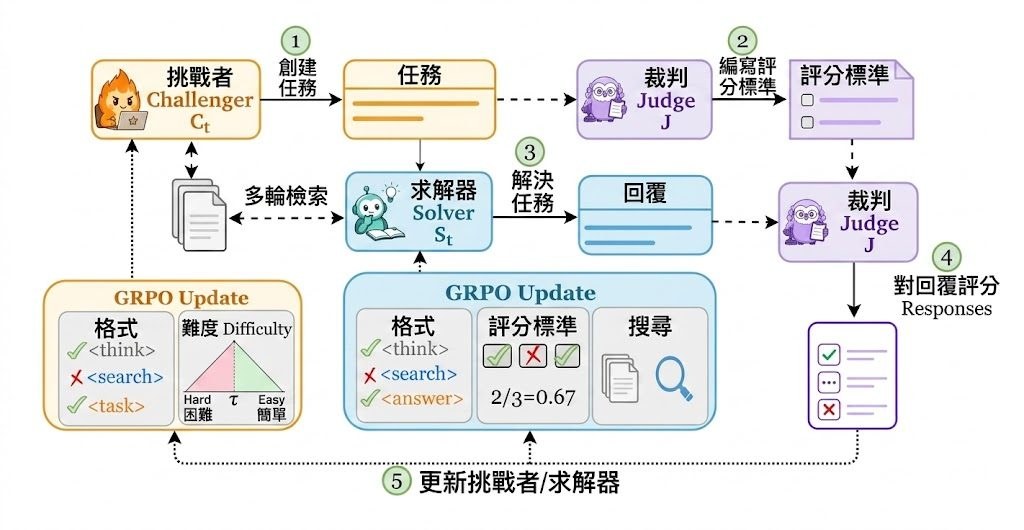
SCOPE 的核心設計是讓同一個基礎模型分身成三個角色:Challenger(出題者)、Solver(答題者)以及 Judge(評判者)。Challenger 讀取一份文件,透過多輪檢索寫出難度貼近答題者極限的題目;Solver 則要靠自己搜尋資料、整合證據後作答;Judge 凍結在初始狀態,根據同一份文件擬定評分準則,並為每項標準給出嚴格的二元評分。三者完全不依賴人工編寫的題目,也不需要體型龐大的前沿模型做監督。
這個框架解決了一個關鍵痛點:開放式任務沒有固定答案,傳統強化學習難以給出可靠的反饋。SCOPE 透過「文件接地」(document grounding)製造資訊不對稱——Challenger 和 Judge 看得到原文,Solver 看不到,迫使答題者必須主動檢索。同時,題目難度被控制在答題者得分約 50% 的位置,因為這個點的反饋變化最大,最有利於學習;得分低於 0.2 或高於 0.8 的題目會被過濾掉,避免太簡單或太難的內容浪費訓練資源。研究亦加入長度懲罰與品質門檻,防止模型以灌水或抄原文的方式「刷分」。
在 Qwen2.5-7B 等 7–8B 規模的模型上,SCOPE 在 8 個開放式基準測試中最高取得 +10.4 分的提升,整體增幅介於 +5.4 至 +10.4 分,並在 7 個傳統問答基準上同樣有穩定進步,過程中使用了 0 條人工策劃的提示。對於想以有限預算微調開源模型、又要兼顧開放式生成品質的開發者與研究團隊,這個方法提供了一條不依賴外部數據集的路徑。