EffOPD 是一個圍繞模型訓練流程改良的研究實作,重點不在做一個全新聊天產品,而是在訓練途中更有效率地挑選值得評估的候選參數。從儲存庫資訊可見,它建基於 verl 與 GOPD,並調整訓練器與工作流程相關檔案,屬於偏底層的優化工具。
實際使用時,做法是沿用原本 OPD 的訓練流程,再加入迭代測試相關設定,並準備一份 parquet 格式的輕量驗證資料。這種安排的意思很直接:模型訓練到某些檢查點時,系統會額外評估幾個外推候選,而不是每次都用完整驗證流程,從而加快判斷。
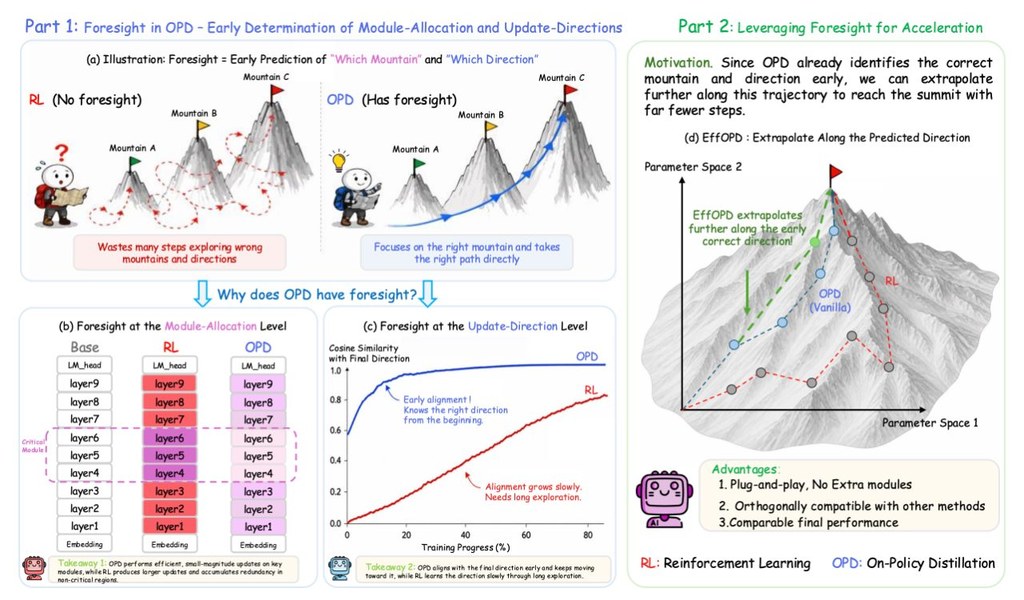
專案想解決的,是大模型強化學習或蒸餾訓練中,評估成本高、嘗試路線多的問題。它較特別的地方,在於把「外推搜尋」和「即時輕量驗證」結合,讓訓練期間可以更早篩走不理想方向;儲存庫亦提到可設定每次最多測試 5 個候選,反映它著重效率與可控性之間的平衡。
- 建基於 verl 與 GOPD,較適合已有相關訓練基礎的人
- 透過啟用迭代測試,在訓練中加入外推式候選搜尋
- 使用 parquet 驗證檔建立輕量驗證集,減少即時評估負擔
- 可調整每個檢查點評估的候選數量,預設實驗值為 5
適合主要作為研究實驗、訓練流程調校,以及想比較不同訓練決策成本的人。相關脈絡上,儲存庫明確提到 OPD、GOPD 和 EffOPD,而論文方向亦圍繞大型語言模型的強化學習動態與 on-policy distillation;對一般用家未必即插即用,但對做模型訓練研究的人有參考價值。