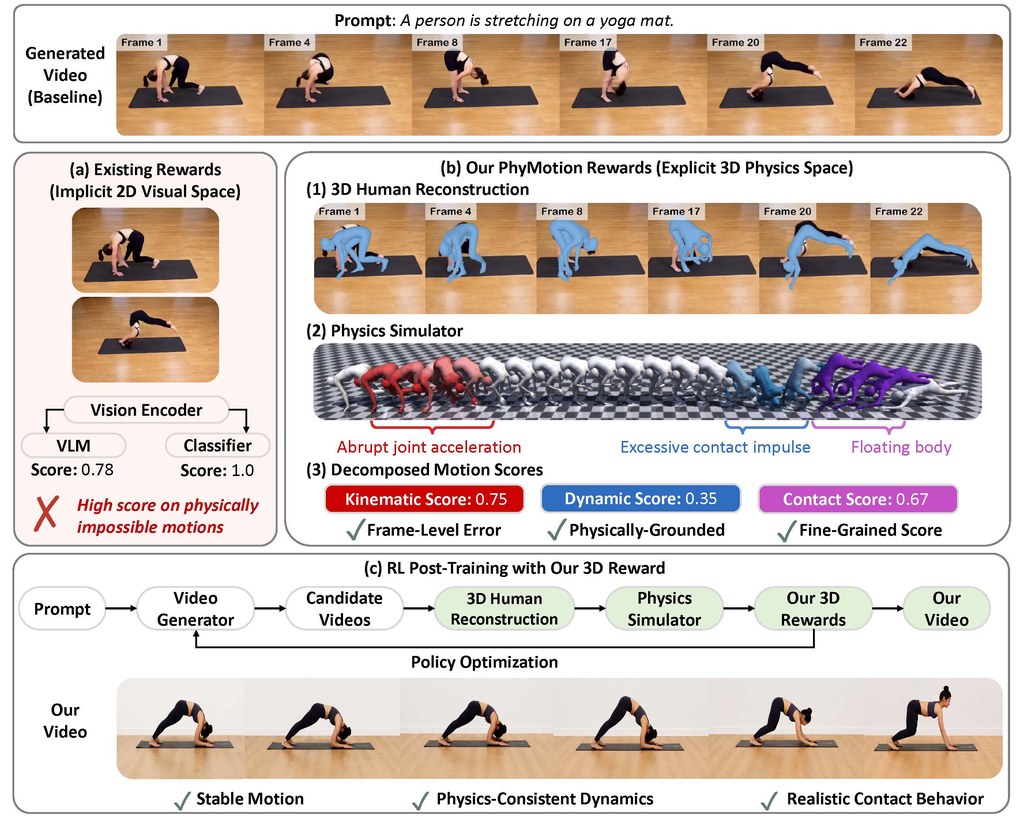
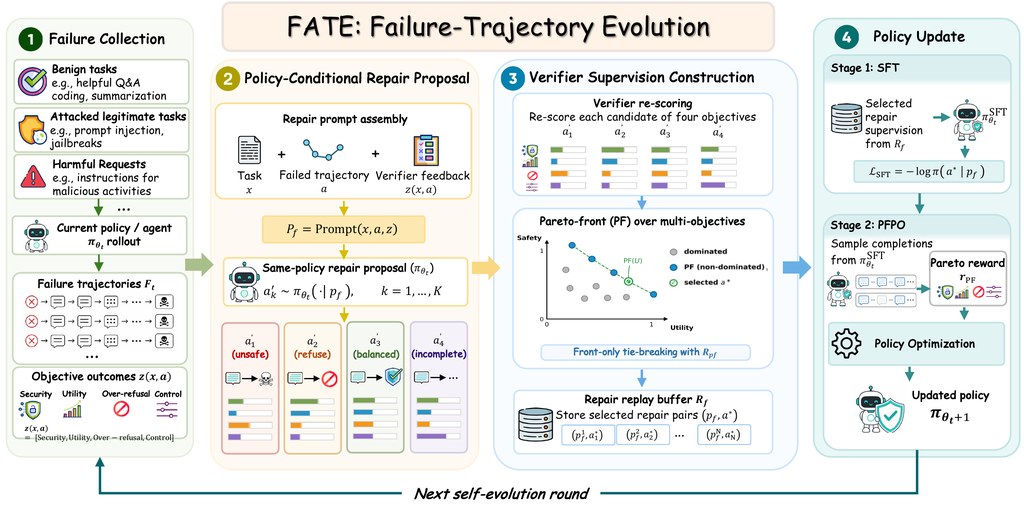
如果你對 AI 影片生成有興趣,但又覺得「要大量素材先訓練」門檻太高,Warp-as-History 的吸引力正在於它嘗試只用一段訓練影片完成相機視角控制。簡單講,它想做的是讓系統學會原片中的空間與運鏡關係,再按你指定的鏡頭路徑生成新畫面。
對一般使用者來說,理解這個專案的最好方法,不是把它當作普通文字生片工具,而是視為一個偏向「鏡頭操控」的研究型方案。你需要先準備一段帶有相機資訊的影片,再配合指定模型做推理或訓練;官方列出的預設組合包括 Helios-Distilled、Warp-as-History LoRA,而 Helios-Mid 主要用於訓練,另外 README 亦提到 Pi3X。
它解決的重點問題,是生成影片時常見的視角不穩、鏡頭移動不連貫,以及難以精準控制觀看方向。這個方法特別強調互動式鏡頭軌跡跟隨與視點調整,定位上與 HappyOyster、Genie 3 這類方向相近,但賣點是把所需訓練資料壓到單一範例,這點相當有研究價值。
- 一段訓練影片 已是核心設定,對資料收集要求較低
- 重心不在純文字生成,而在鏡頭路徑與視角控制
- 相關模型包括 Helios-Distilled、Warp-as-History LoRA、Helios-Mid、Pi3X
- 較適合研究實驗、效果驗證,未必是即開即用的消費級工具
如果你是做生成式影像研究、互動敘事、虛擬攝影,這個專案值得留意;若你只是想快速剪片或一鍵出成品,可能會覺得前置準備仍然偏技術性。整體來看,Warp-as-History 最有意思的地方,是把「影片歷史資訊」由單純上下文提升為可延續的視角依據,令相機控制這件事更像真正可操作的生成條件。