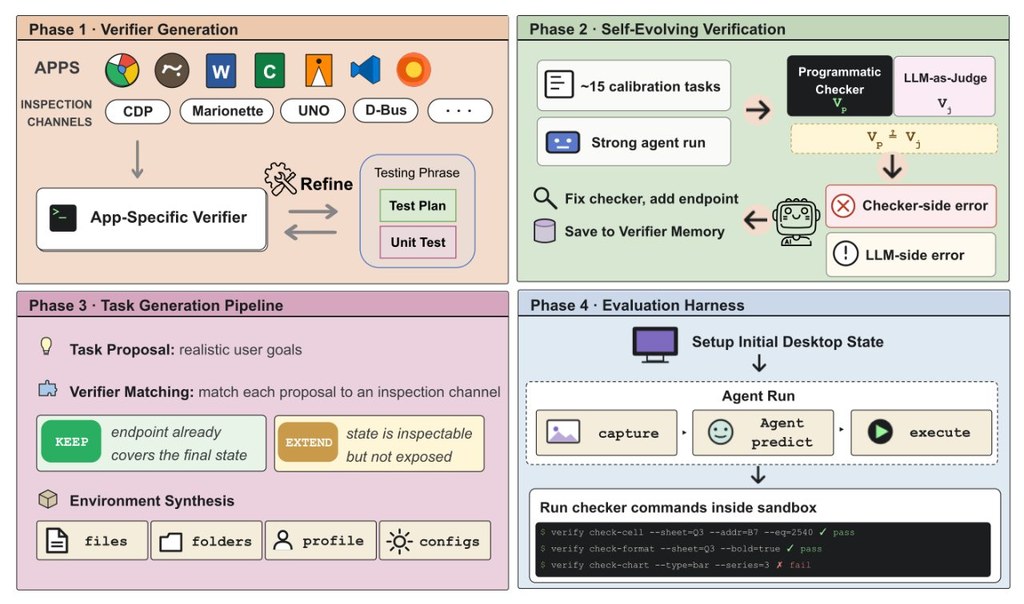
OpenComputer 主要處理一個很實際的難題:當 AI 代理要打開瀏覽器、改文件、用設計工具或整理檔案時,怎樣才算「真的完成任務」?它不是靠主觀判斷,而是為不同桌面軟件建立可檢查的狀態驗證方式,令評測結果更穩定,也較容易重現。
動手使用時,重點不是直接把它當成一般應用程式安裝,而是按專案提供的環境設定範本準備評測環境,再選擇本機沙盒或雲端後端,之後用現成任務去跑代理測試。專案亦分開了修復評測、AWS 遠端 Docker 與 Tencent Cloud 中國區部署文件,明顯是為較正式的實驗流程而設。
它最有意思的地方,在於把「出題」和「判卷」都系統化。除了為應用程式建立檢查端點,還會自動生成較真實、可機器驗證的桌面任務,並記錄整段操作軌跡,連部分完成的進度都可計分;比起只看最後答案,這種做法更適合分析代理卡在哪一步。
- 覆蓋 33 個桌面應用程式與 1,000 個已定稿任務
- 場景包括瀏覽器、文書、創作工具、開發環境、檔案管理與通訊軟件
- 評測不只看成敗,亦會保留操作過程與部分分數
- 驗證方式較依賴程式化檢查,不單靠語言模型做裁判
專案適合做 AI 代理、桌面自動化、基準測試或研究評估方法的團隊;一般用家未必會直接拿來日常使用。從論文內容看,相關對比亦涉及 frontier agents、open-source models,以及 OSWorld-Verified 這類評測結果,反映它比較像研究基建,而不是單一模型展示頁。整體而言,OpenComputer 的價值在於把電腦操作代理的評測,從「似乎做到」推進到「可以核實做到多少」。