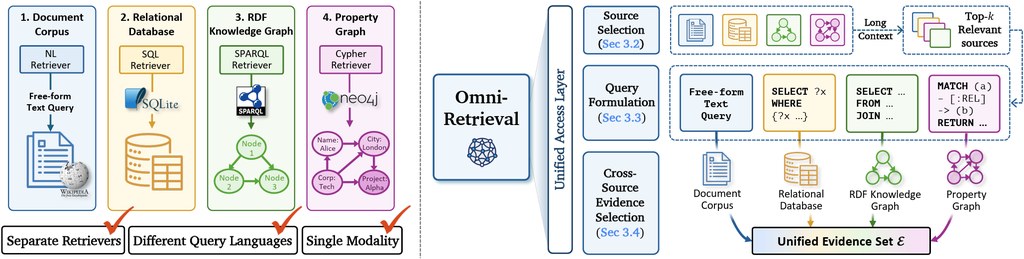
OmniRetrieval 想處理的,是資料散落在不同系統時的查詢麻煩。一般檢索工具多數只懂一種來源,但這個項目會先理解自然語言問題,再挑選合適知識來源,為各來源生成對應查詢,最後合併結果。
使用這個項目時,核心流程分成 route、generate、execute、select 四步:先選來源,再寫出來源原生查詢,之後執行,最後從多份結果中挑出較合適的證據。對非研究用途讀者來說,可把它理解成一個「跨系統問答協調層」,放在文字語料、SQL、SPARQL、Cypher 之上。
它的重點不在把所有資料硬轉成同一格式,而是保留各種來源原本的表達能力。這種做法能保住關聯式資料庫的 schema、RDF knowledge graph 的 ontology,以及 property graph 的圖結構查詢能力,避免統一格式後反而損失資訊。
- 支援四類來源:free-form text、SQL、SPARQL、Cypher
- 基準涵蓋 13 個資料集、309 個 distinct knowledge bases
- 可量度 source selection accuracy,以及 query formulation 的 exact match 與 token-level F1
- 提供 LLM provider 選擇,文中可見 openai 與本地 vllm 設定
- 相關資料集包括 BEIR、Spider、BIRD、LC-QuAD 2.0、QALD-10、SimpleQuestions、Text2Cypher
表現方面,來源資料指出 OmniRetrieval 在跨來源基準上超越 single-source baselines,但不同模型、資料預處理和外部執行環境都會影響結果。從項目結構看,它較適合研究 heterogeneous knowledge retrieval、企業內多資料源問答,或想測試 Large Language Model 如何生成 SQL、SPARQL、Cypher 的開發者。至於模型,項目至少提到 openai 預設骨幹與可本地運行的 vllm,示例亦出現 Qwen/Qwen3.5-4B。