處理長影片時,視覺語言模型 (VLM) 一次只能看幾幀畫面,於是「要挑哪幾幀」就成了影片標題生成的瓶頸。PEEK 這個開源項目正是為了解決這個問題:它是一個 query-free 的影格挑選器,專為低預算 (low-budget) 影片標題任務而設計。
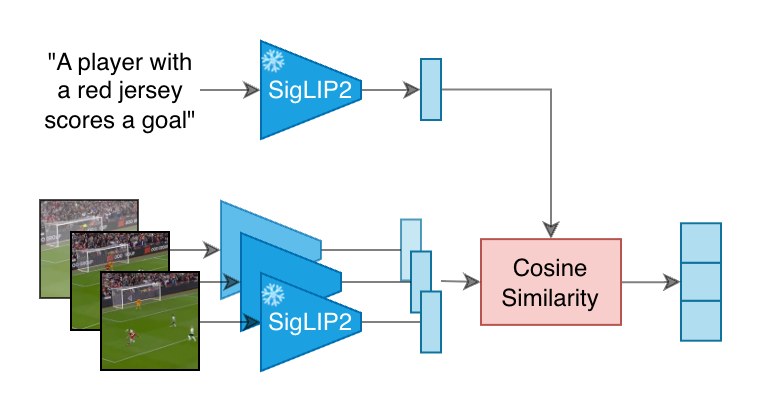
PEEK 的運作分為兩階段。第一階段由凍結的 SigLIP2 SO400M patch14 384 雙編碼器擔任教師模型,利用真實標題與每一幀計算餘弦相似度,並做最小最大正規化 (min-max normalization),產生幀級相關性分數。第二階段是一個 2 層 Transformer 學生模型,接收凍結的 MobileCLIP2-S0 幀嵌入,以 ListMLE 排序損失 (listwise ranking loss) 學習重現教師的排序。推論時學生模型只需看畫面,無需任何標題或文字編碼器介入。
選幀策略採用「分組取最大」(stratified argmax):將影片均分成 k 個時間區段,每段挑出分數最高的幀,以兼顧時間分佈。當 k=1 時則退化為全影片取最大。
實驗結果顯示,單一在 ActivityNet 訓練的 PEEK 權重在多個影片標題 VLM 上,於一幀與兩幀設定的 CIDEr 分數均優於均勻取樣,且預算越緊、省下的時間越多。論文亦報告 PEEK 在標題生成流程中僅增加 5.2% 時間,相比 CSTA 的 65.4% 與 MaxInfo 的 211.9% 更為輕量。
適合需要快速處理大量影片的研發團隊、影片摘要系統開發者,以及想為現有 VLM 加上智能取樣的研究者。倉庫已提供教師分數生成、蒸餾訓練、單段影片推論 CLI 與 Python API,並於 Hugging Face 釋出 ActivityNet 訓練的 base 權重。
重點摘要
- 問題:VLM 處理影片時,如何在極少影格預算下挑出最有資訊量的畫面。
- 方法:以 SigLIP2 為教師產生排序標籤,再以 MobileCLIP2 + 2 層 Transformer 學生模型做知識蒸餾 (knowledge distillation)。
- 推論:無需文字查詢,僅靠視覺證據;採用 stratified argmax 兼顧時間覆蓋。
- 效率:額外開銷僅約 5.2%,遠低於 CSTA 與 MaxInfo 等自適應方法。
- 資源:開源訓練與推論代碼,並提供 Hugging Face 預訓練權重。