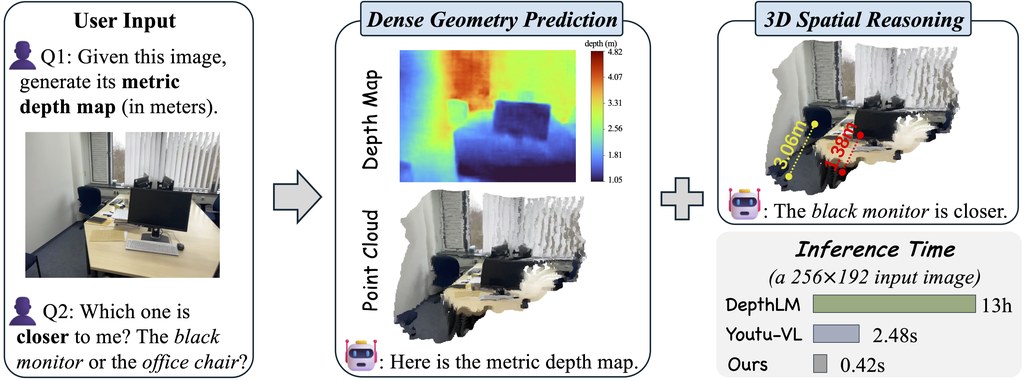
如果你曾經好奇電腦點樣由一張相片判斷物件有幾遠,DepthVLM 就係一個幾有代表性的答案。呢個專案主打由單張圖片直接輸出具實際尺度的深度資訊,同時保留問答、理解畫面內容等多模態能力,唔係只做單一視覺任務。
對一般開發者而言,上手方向算清晰:程式碼、模型權重同基準資料都已有公開入口,亦提供示例視覺化結果方便先睇效果。要留意資料本身受授權限制,作者未有直接派發整理後全集,但有公開資料整理流程,較適合願意自己重現訓練或評估的人。
佢較特別之處,在於唔需要將「睇圖理解」同「估深度」拆開做。論文資訊顯示,DepthVLM 會喺單次推理中同時產生深度圖與文字輸出,並以輕量模組接到語言模型骨幹上,速度亦比同類 VLM 方案如 DepthLM、Youtu-VL 更快。
如果你做機械人、AR/VR、室內導航,或者想研究影像中的 3D 空間推理,呢類模型特別有價值。從公開內容看,相關比較對象包括 DepthLM-12B、Youtu-VL-4B、InternVL3.5-38B,以及偏純視覺路線的 Depth Anything V3、UniDepth V2、Metric3D v2、Depth Pro、ZoeDepth。
- 一個模型兼顧畫面理解與深度預測
- 可輸出具米制尺度的稠密深度圖
- 推理效率強調比部分現有 VLM 更快
- 已提供範例、模型檔與基準標註入口
- 較適合研究、實驗同進階應用整合
整體來講,DepthVLM 吸引之處唔單止係準確度,而係它試圖將 3D 感知正式帶入視覺語言模型工作流。若你想搵一個連接「識答問題」同「識判斷空間距離」的方案,呢個專案相當值得先收藏再深入試用。