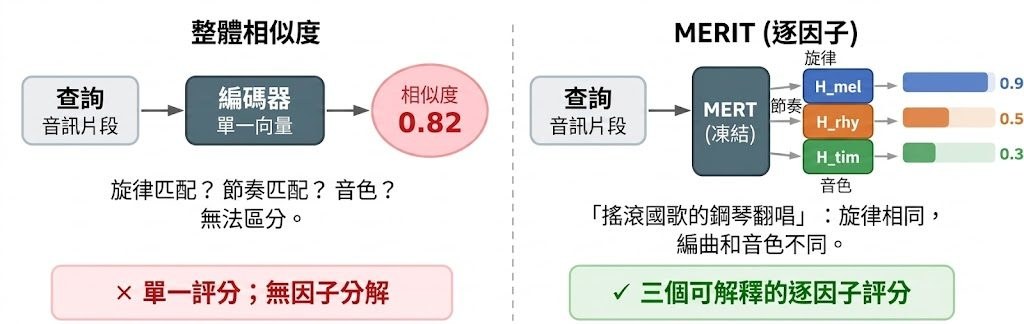
現有的音樂相似度模型大多只輸出一個籠統的總分,把旋律、節奏、音色混在一起計算,使用者很難說明「為何這兩首歌像」。MERIT(Multi-Factor Disentangled Music Similarity)由新加坡科技與設計大學的 AMAAI 實驗室推出,以凍結的 MERT backbone 為基礎,再訓練三個各約 11 MB 的輕量投影頭(projection heads),分別負責旋律(S_mel)、節奏(S_rhy)、音色(S_tim)。一段鋼琴翻唱搖滾歌曲的音檔,會在旋律分數偏高、節奏和音色分數偏低,差異即時可見。
這個項目解決的核心問題是音樂檢索的可解釋性。傳統 CLAP、MuLan 或 MERT 這類自監督音訊模型把多種特徵壓縮到同一向量,餘弦相似度難以拆解;MERIT 改用條件式音訊生成與音源分離技術,自動產生 296K 組「單一變因」三元組訓練資料,免去人工標註。三個頭在 held-out 測試中都達到 ≥99.6% 的三元組準確率,並在零樣本真實音訊探測中各自主導對應的感知維度。
重點摘要:
- 把相似度拆成旋律、節奏、音色三條獨立訊號
- 採用凍結 MERT-v1-330M 主幹,僅訓練小型投影頭
- 透過生成式管線產生 296K 因子控制三元組,無需人工標註
- 每個頭約 11 MB,總計約 33 MB,方便部署
- 預訓練權重與資料集已發布於 HuggingFace
合適的場景包括音樂串流平台的進階推薦、音樂學研究中的跨版本比較,以及需要解釋「為何推薦這首」的場景。對一般使用者而言,把 S_mel 較高的曲目組成「同一旋律」歌單,就能體驗到差異。
運作流程相當直接:下載三個 .pt 投影頭,以 Wav2Vec2FeatureExtractor 讀入音檔,從 MERT 指定的第 3、4、5、6、23 層抽取特徵,分別送入三個頭即可得到三組 embedding,再以餘弦相似度比較。模型與資料集皆已開源,有興趣的開發者可從 HuggingFace 取得 amaai-lab/merit 與對應資料集。