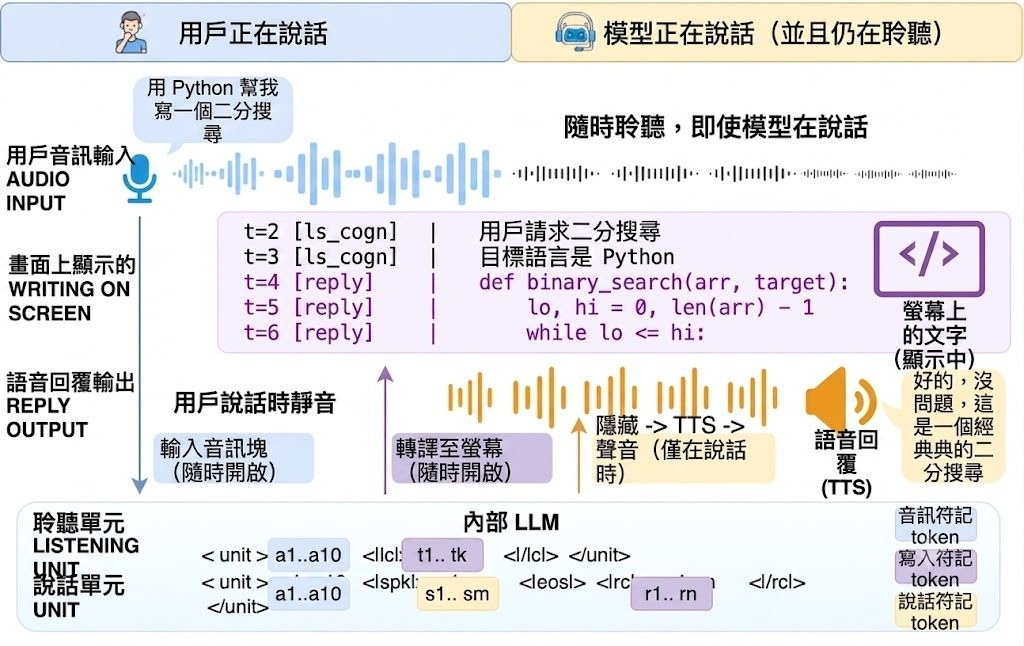
一般語音大型語言模型只能說出口頭回應,許多文字擅長的工作(例如編寫程式、條列分析、逐步推理)在即時對話中往往被犧牲。Listen-Write-Speak(LWS)正是針對這個瓶頸而設計,它讓單一自回歸大型語言模型同時處理三個通道:持續聆聽使用者音訊、即時生成可見的文字、並行輸出語音回應,三者共享同一個因果注意力脈絡。
這是模型、框架,還是什麼? LWS 是一個完整的語音模型項目,包含推理服務、Triplex/LWS runtime、前端展示以及測試,並非單純的網頁展示殼層。它建基於 OpenBMB 的 MiniCPM-o-4_5,再透過 Token Schema 機制在不改動模型架構的前提下,把文字輸出提升為第一公民的通道。
創新之處在於打破了「文字只是隱藏中間狀態」的慣例:寫入螢幕的內容不再只是語音的草稿,而是可被檢視、可被複製、可被審核的正式輸出。這對於需要邊說邊整理思緒的場景特別有幫助,例如教學、編程輔助、會議摘要。
性能與評估方面,項目在 VoiceBench AlpacaEval 達到 4.72 分,書寫與語音一致性為 92.6%,並在 Full-Duplex-Bench 與多語言 URO-Bench 都有穩定表現,顯示三通道並行並未犧牲即時反應。
適合的對象包括研究語音介面的開發者、需要可審核對話紀錄的團隊,以及對全雙工(full-duplex)互動有興趣的 AI 工程師。如想測試,可透過 ModelScope 下載基座模型 OpenBMB/MiniCPM-o-4_5 與 LWS 資產後運行推理服務與前端展示。
重點摘要:
- 三通道並行:聆聽、可見書寫、語音輸出共享一個因果注意力脈絡
- 文字優先:寫入內容是第一公民輸出,不再是隱藏草稿
- 無需改架構:透過 Token Schema 在標準自回歸 LLM 上實現
- 完整開源 runtime:包含推理服務、runtime 與前端,非單純展示
- 多項基準驗證:在 Full-Duplex-Bench、VoiceBench、URO-Bench 均有報告數據