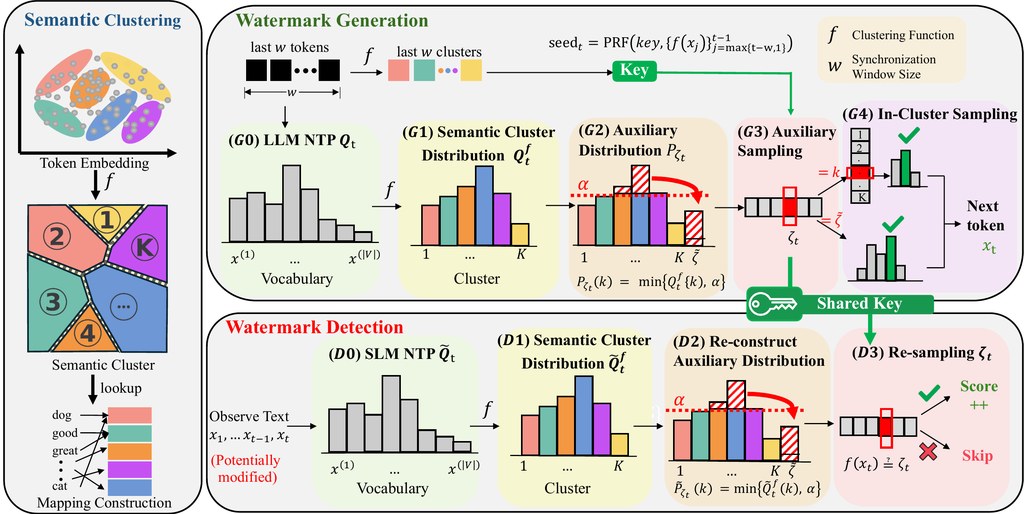
PASA 是一個研究型專案,目標是替大型語言模型生成的文字加入可檢測的「水印」。它特別針對一個常見難題:即使用家把句子改寫、換同義詞,甚至做段落重述,只要意思大致不變,系統仍希望辨認到這段文字原本由 AI 產生。
和不少只看字面詞彙的做法不同,PASA 把重點放在語意層面。簡單講,它不是只標記某些字,而是利用嵌入空間中的語意群組去安排生成與檢測,因此面對 paraphrase 這類「保留意思但改寫表達」的攻擊時,理論上會更穩定。
實際使用上,這個儲存庫主要提供研究重現流程:用 generation.py 進行生成與檢測,並配合語言模型、輔助模型、本地資料集及一份 token 對應語意群組的映射檔來跑實驗。換句話說,它比較適合研究人員或進階開發者驗證效果,而不是一般用家即裝即用的成品工具。
重點可簡單整理如下:
– 針對 AI 文字加入可檢測水印,並強調抗改寫能力
– 核心創新是把水印放到語意嵌入空間,不只看表面用字
– 設計目標包括提升檢測穩定性,同時盡量維持文字品質
– 儲存庫提供官方實作,重點在實驗重現與結果驗證
如果你的場景是內容來源追蹤、平台風險管理,或學術上研究 AI 文字識別,PASA 會很值得留意。相反,若你只是想快速做網站內容偵測,這個專案目前看來仍偏研究導向,需要自行準備資料與模型環境。
從論文與專案說明來看,PASA 的價值不只在「能不能驗出」,而是在改寫攻擊下仍保持可檢測性,這點對現實應用尤其重要。不過它是否適合你的流程,仍要視乎你有沒有能力配置實驗環境,以及是否需要面對高強度的語意改寫情境。